etcd Backup (OpenShift Container Platform)
Assuming the Kubernetes cluster is set up through OpenShift Container Platform,
the etcd pods will be running in the openshift-etcd namespace.
Before taking a backup of the etcd cluster, a Secret needs to be created
in a temporary new or an existing namespace, containing details about
the etcd cluster endpoint, etcd pod labels and namespace in which the etcd pods
are running. In the case of OCP, it is likely that etcd pods have
labels app=etcd,etcd=true and are running in the namespace
openshift-etcd.
A temporary namespace, and a Secret to access the etcd member can be created by
running the following commands:
$ oc create ns etcd-backup
$ oc create secret generic etcd-details \
--from-literal=endpoints=https://10.0.133.5:2379 \
--from-literal=labels=app=etcd,etcd=true \
--from-literal=etcdns=openshift-etcd \
--namespace etcd-backup
Note
Make sure that the provided endpoints, labels and etcdns values
are correct. K10 uses the labels provided above to identify a member of the
etcd cluster and then takes backup of the running etcd cluster.
To figure out the value for endpoints flag, the below command can be used:
$ oc get node -l node-role.kubernetes.io/master="" -ojsonpath='{.items[0].status.addresses[?(@.type=="InternalIP")].address}'
To avoid any other workloads from etcd-backup namespace being backed
up, Secret etcd-details can be labeled to make sure only this Secret
is included in the backup. The below command can be executed to label the
Secret:
$ oc label secret -n etcd-backup etcd-details include=true
Backup
To create the Blueprint resource that will be used by K10 to backup etcd, run the below command:
$ oc --namespace kasten-io apply -f \
https://raw.githubusercontent.com/kanisterio/kanister/0.109.0/examples/etcd/etcd-in-cluster/ocp/blueprint-v2/etcd-incluster-ocp-blueprint.yaml
Alternatively, use the Blueprints page on K10 Dashboard to create the Blueprint resource.
Once the Blueprint is created, the Secret that was created above needs to be annotated to instruct K10 to use this Secret with the provided Blueprint to perform backups on the etcd pod. The following command demonstrates how to annotate the Secret with the name of the Blueprint that was created earlier.
$ oc annotate secret -n etcd-backup etcd-details kanister.kasten.io/blueprint='etcd-blueprint'
secret/etcd-details annotated
Once the Secret is annotated, use K10 to backup etcd using the new namespace. If the Secret is labeled, as mentioned in one of the previous steps, while creating the policy, just that Secret can be included in the backup by adding resource filters like below:
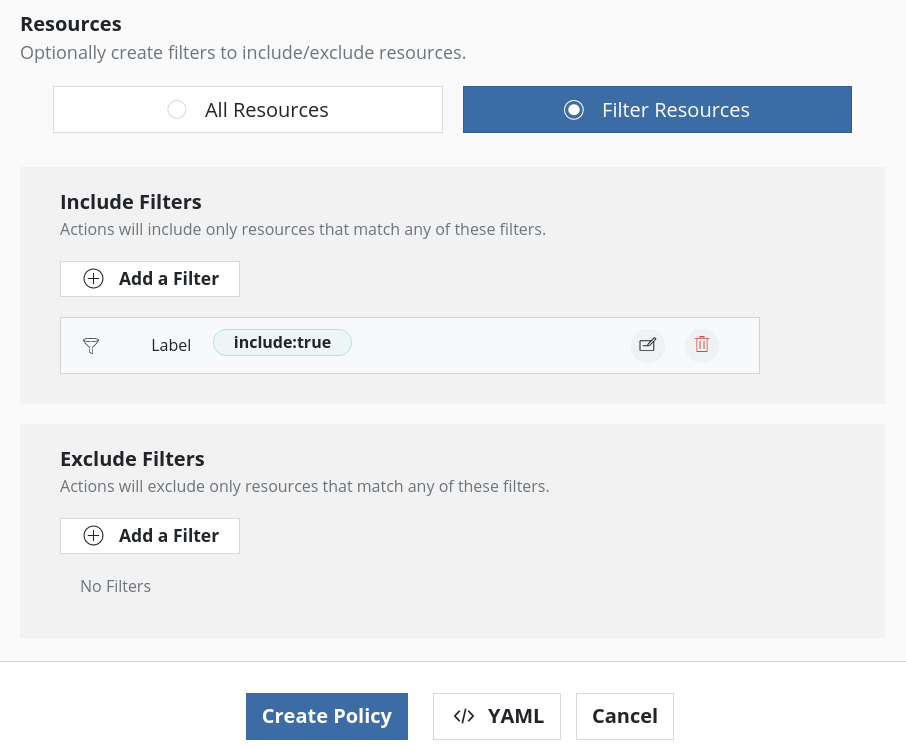
Note
The backup location of etcd can be found by looking at the Kanister artifact of the created restore point.
Restore
To restore the etcd cluster, the same mechanism that is documented by
OpenShift
can be followed with minor modifications. The OpenShift documentation provides
a cluster restore script (cluster-restore.sh), and that restore script
requires minor modifications as it expects the backup of static pod
manifests as well which is not taken in this case. The modified version of
the restore script can be found on here.
Before starting the restore process, make sure these prerequisites are met:
Create a namespace (for example
etcd-restore) where K10 restore would be executed$ oc create namespace etcd-restore
Create a Persistent Volume and Persistent Volume Claim in the namespace
etcd-restorecreated in the above step. These resources are needed to copy backed-up etcd data to the leader node to perform restore operation$ oc --namespace etcd-restore apply -f \ https://raw.githubusercontent.com/kanisterio/kanister/0.109.0/examples/etcd/etcd-in-cluster/ocp/blueprint-v2/pv-etcd-backup.yaml
$ oc --namespace etcd-restore apply -f \ https://raw.githubusercontent.com/kanisterio/kanister/0.109.0/examples/etcd/etcd-in-cluster/ocp/blueprint-v2/pvc-etcd-backup.yaml
SSH connectivity to all the leader nodes
Among all the leader nodes, choose one node to be the restore node. Perform the steps below to download the etcd backup file to the chosen restore node:
Add a label
etcd-restoreto the node that has been chosen as the restore node$ oc label node <your-leader-node-name> etcd-restore=true
Perform the restore action on K10 by selecting the target namespace as
etcd-restore. The K10 restore action in this step only downloads the backup file from the external storage to the restore node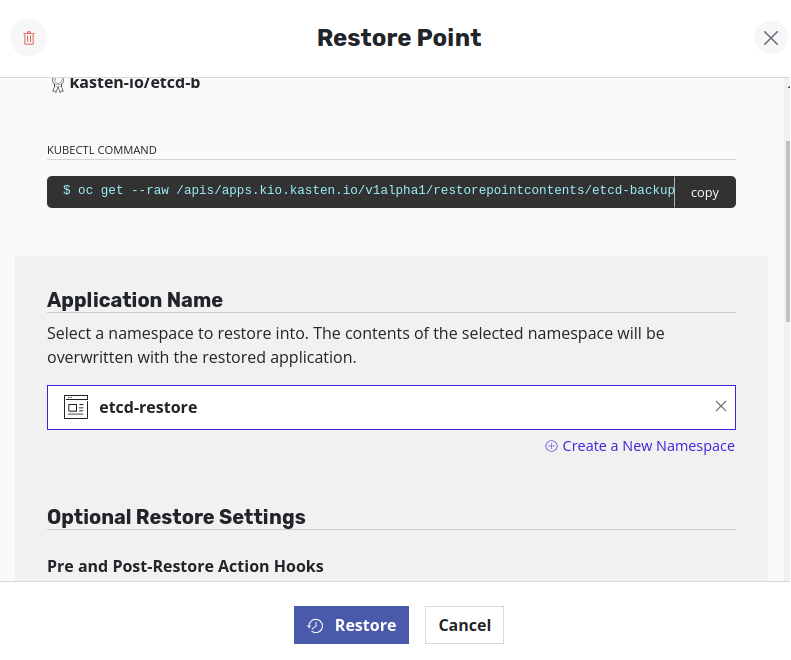
The below steps should be followed to restore the etcd cluster:
Check if the the backup file is downloaded and available at
/mnt/datalocation on the restore nodeStop static pods from all other leader nodes by moving them outside of
staticPodPathdirectory (i.e.,/etc/kubernetes/manifests):# Move etcd pod manifest $ sudo mv /etc/kubernetes/manifests/etcd-pod.yaml /tmp # Make sure etcd pod has been stopped. The output of this # command should be empty. If it is not empty, wait a few # minutes and check again. $ sudo crictl ps | grep etcd | grep -v operator # Move api server pod manifest $ sudo mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmp # Verify that the Kubernetes API server pods are stopped. The output of # this command should be empty. If it is not empty, wait a few minutes # and check again. $ sudo crictl ps | grep kube-apiserver | grep -v operator
Move the etcd data directory to a different location, on all leader nodes that are not the restore nodes:
$ sudo mv /var/lib/etcd/ /tmp
Run the modified
cluster-ocp-restore.shscript with the location of etcd backup:$ sudo ./cluster-ocp-restore.sh /mnt/data
Check the nodes to ensure they are in the
Readystate.$ oc get nodes -w NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.23.3+e419edf host-172-25-75-38 Ready worker 3d20h v1.23.3+e419edf host-172-25-75-40 Ready master 3d20h v1.23.3+e419edf host-172-25-75-65 Ready master 3d20h v1.23.3+e419edf host-172-25-75-74 Ready worker 3d20h v1.23.3+e419edf host-172-25-75-79 Ready worker 3d20h v1.23.3+e419edf host-172-25-75-86 Ready worker 3d20h v1.23.3+e419edf host-172-25-75-98 Ready worker 3d20h v1.23.3+e419edf
If any nodes are in the
NotReadystate, log in to the nodes and remove all of the PEM files from the/var/lib/kubelet/pkidirectory on each node.Restart the
Kubeletservice on all of the leader nodes:$ sudo systemctl restart kubelet.service
Approve the pending CSRs (If there are no CSRs, skip this step)
# Check for any pending CSRs $ oc get csr # Review the details of a CSR to verify that it is valid $ oc describe csr <csr_name> # Approve all the pending CSRs $ oc adm certificate approve <csr_name>
On the restore node, verify that the etcd container is running
$ sudo crictl ps | grep etcd | grep -v operator
Verify that the single etcd node has been started by executing following command from a host which can access the cluster
$ oc get pods -n openshift-etcd | grep -v etcd-quorum-guard | grep etcd NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47s
Delete and recreate other lost leader machines, one by one. After these machines are recreated, a new revision is forced and etcd scales up automatically. If you are running installer-provisioned infrastructure, or you used the Machine API to create your machines, follow these steps. Otherwise, you must create the new control plane node using the same method that was used to originally create it.
Note
Do not delete and recreate the machine for the recovery(restore node) host
$ oc get machines -n openshift-machine-api -o wide NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running # Save the machine configuration of lost control plane node to a file # on your file system $ oc get machine clustername-8qw5l-master-0 -n openshift-machine-api \ -o yaml > new-master-machine.yaml # Edit the new-master-machine.yaml file that was created in the previous step # to assign a new name and remove unnecessary field 1. Remove the entire status section 2. Change the metadata.name field to a new name 3. Remove the spec.providerID field 4. Remove the metadata.annotations and metadata.generation fields 5. Remove the metadata.resourceVersion and metadata.uid fields # Delete the machine of the lost control plane host $ oc delete machine -n openshift-machine-api clustername-8qw5l-master-0 # Verify that the machine was deleted $ oc get machines -n openshift-machine-api -o wide # Create the new machine using the new-master-machine.yaml file $ oc apply -f new-master-machine.yaml # Verify that the new machine has been created. # The new machine will be ready after phase changes from Provisioning to Running $ oc get machines -n openshift-machine-api -o wide
Force etcd deployment, by running the below command:
$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge # Verify all nodes are updated to latest version $ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}' # To make sure all etcd nodes are on the latest version wait for a message like below AllNodesAtLatestRevision 3 nodes are at revision 3
Force rollout for the API Server control plane component:
# API Server $ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge
Wait for all API server pods to get to the latest revision:
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'
Force rollout for the Controller Manager control plane component:
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge
Wait for all Controller manager pods to get to the latest revision:
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'
Force rollout for the Scheduler control plane component:
$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge
Wait for all Scheduler pods to get to the latest revision:
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'
Verify that all the etcd pods are in the running state. If successful, the etcd cluster has been restored successfully
$ oc get pods -n openshift-etcd | grep -v etcd-quorum-guard | grep etcd
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h
etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h
etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h