Protecting Applications
Protecting an application with Veeam Kasten, usually accomplished by creating a policy, requires the understanding and use of three concepts:
- Snapshots and Exports: Depending on the environment and requirements, one or both of these data capture mechanisms will be used
- Scheduling: Specification of application capture frequency and snapshot/backup retention objectives
- Selection: This defines not just which applications are protected by a policy but, whenever finer-grained control is needed, resource filtering can be used to select what is captured on a per-application basis
This section demonstrates how to use these concepts in the context of a Veeam Kasten policy to protect applications. Today, an application for Veeam Kasten is defined as a collection of namespaced Kubernetes resources (e.g., ConfigMaps, Secrets), relevant non-namespaced resources used by the application (e.g., StorageClasses), Kubernetes workloads (i.e., Deployments, StatefulSets, OpenShift DeploymentConfigs, and standalone Pods), deployment and release information available from Helm v3, and all persistent storage resources (e.g., PersistentVolumeClaims and PersistentVolumes) associated with the workloads.
For protecting Virtual Machines (VMs) running on KubeVirt-based platforms like Red Hat OpenShift Virtualization or SUSE Virtualization (Harvester), Veeam Kasten also supports VM-based policies that allow fine-grained protection of individual VMs without backing up entire namespaces. See VM-Based Backup Policies for details.
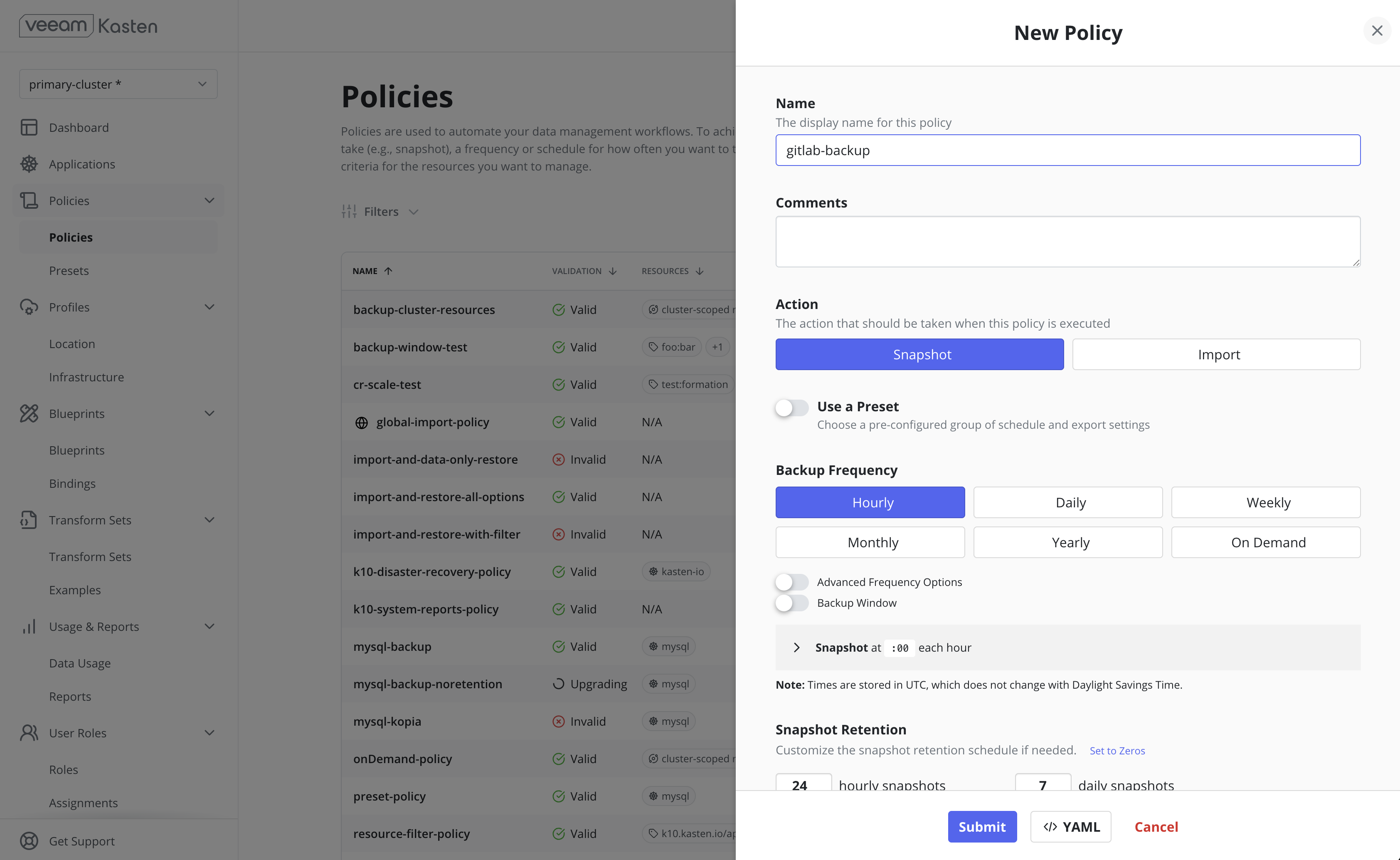
Creating a new policy may be performed via either the Policies or Applications page. Initiating policy creation from the Applications page will pre-populate fields for policy name and namespace selection.
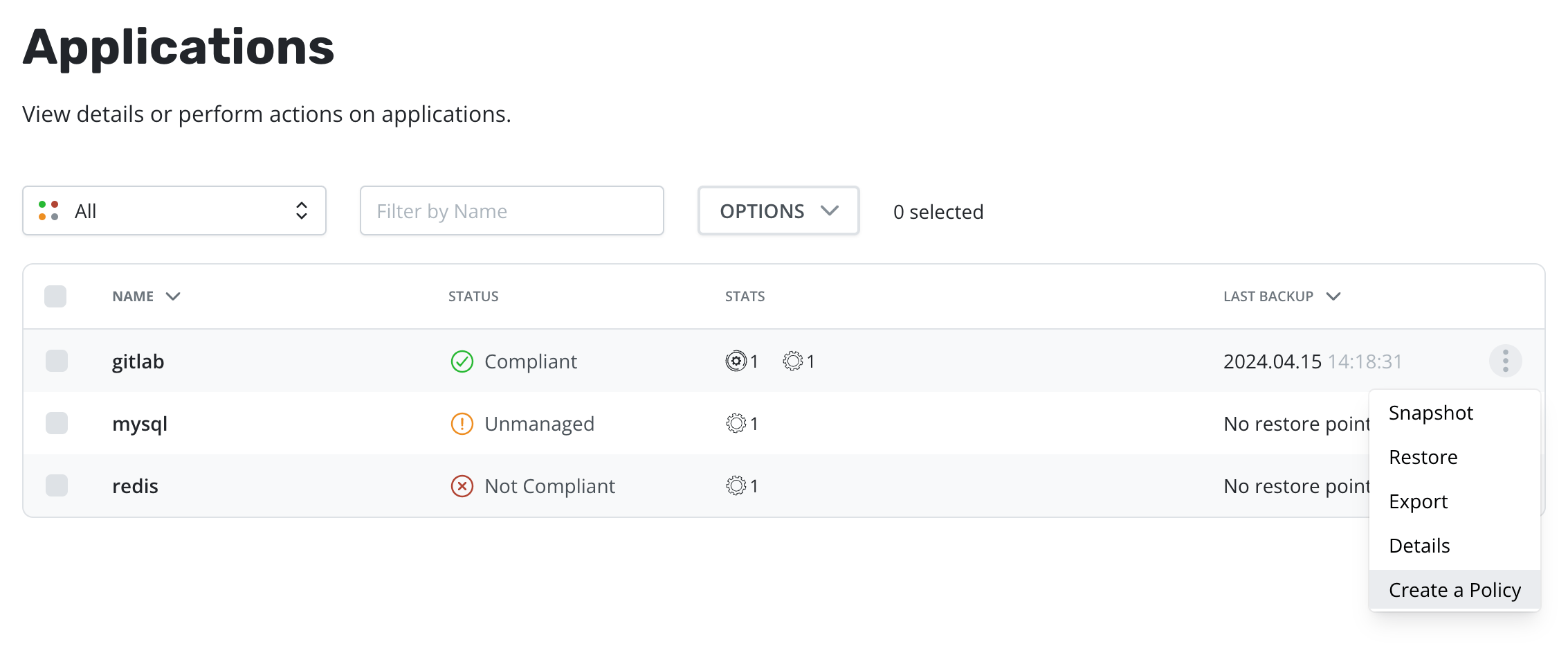
First, go to the Applications page by clicking on the Applications card on the main dashboard or using the Applications navigation link the sidebar.
Next, find any unmanaged application in the Application table and select the Create a Policy menu option to navigate to the policy creation form, where the auto-populated policy name will be provided and can be modified as needed.
Snapshots and Exports
All policies center around the execution of actions and, for protecting applications, you start by selecting the snapshot action with an optional export action to produce a durable backup.
Snapshots
Snapshots are the basis of persistent data capture in Veeam Kasten. They are usually used in the context of disk volumes (PVC/PVs) used by the application but can also apply to application-level data capture (e.g., with Kanister).
Snapshots, in most storage systems, are very efficient in terms of having a very low performance impact on the primary workload, requiring no downtime, supporting fast restore times, and implementing incremental data capture.
However, storage snapshots usually also suffer from constraints such as having relatively low limits on the maximum number of snapshots per volume or per storage array. Most importantly, snapshots are not always durable. First, catastrophic storage system failure will destroy your snapshots along with your primary data. Further, in a number of storage systems, a snapshot's lifecycle is tied to the source volume. So, if the volume is deleted, all related snapshots might automatically be garbage collected at the same time. It is therefore highly recommended that durable backups be created by exporting data.
A number of public cloud providers (e.g., AWS, Azure, Google Cloud) actually store snapshots in object storage and they are retained independent of the lifecycle of the primary volume. However, this is not true of all public clouds (e.g., IBM Cloud) and you might also need to enable exports in public clouds for safety. Please check with your cloud provider's documentation for more information.
Exports
Given the limitations of snapshots, it is often advisable to set up backups of your application stack. However, even if your snapshots are durable, backups might still be useful in a variety of use cases including lowering costs with Veeam Kasten's data deduplication or backing your snapshots up in a different infrastructure provider for cross-cloud resiliency.
Backup operations convert application and volume snapshots into backups by transforming them into an infrastructure-independent format and then storing them in a target location.
The resulting exported data is organized into storage repositories that are exclusively controlled and maintained by the Veeam Kasten instance. Independently using, interacting, connecting, modifying, copying, upgrading, or in any way accessing/manipulating a Veeam Kasten storage repository is unsupported and might cause data corruption/loss to some or all of the restore points. Users must never attempt to perform any such action themselves unless under constant, active supervision by a member of Veeam support or engineering teams.
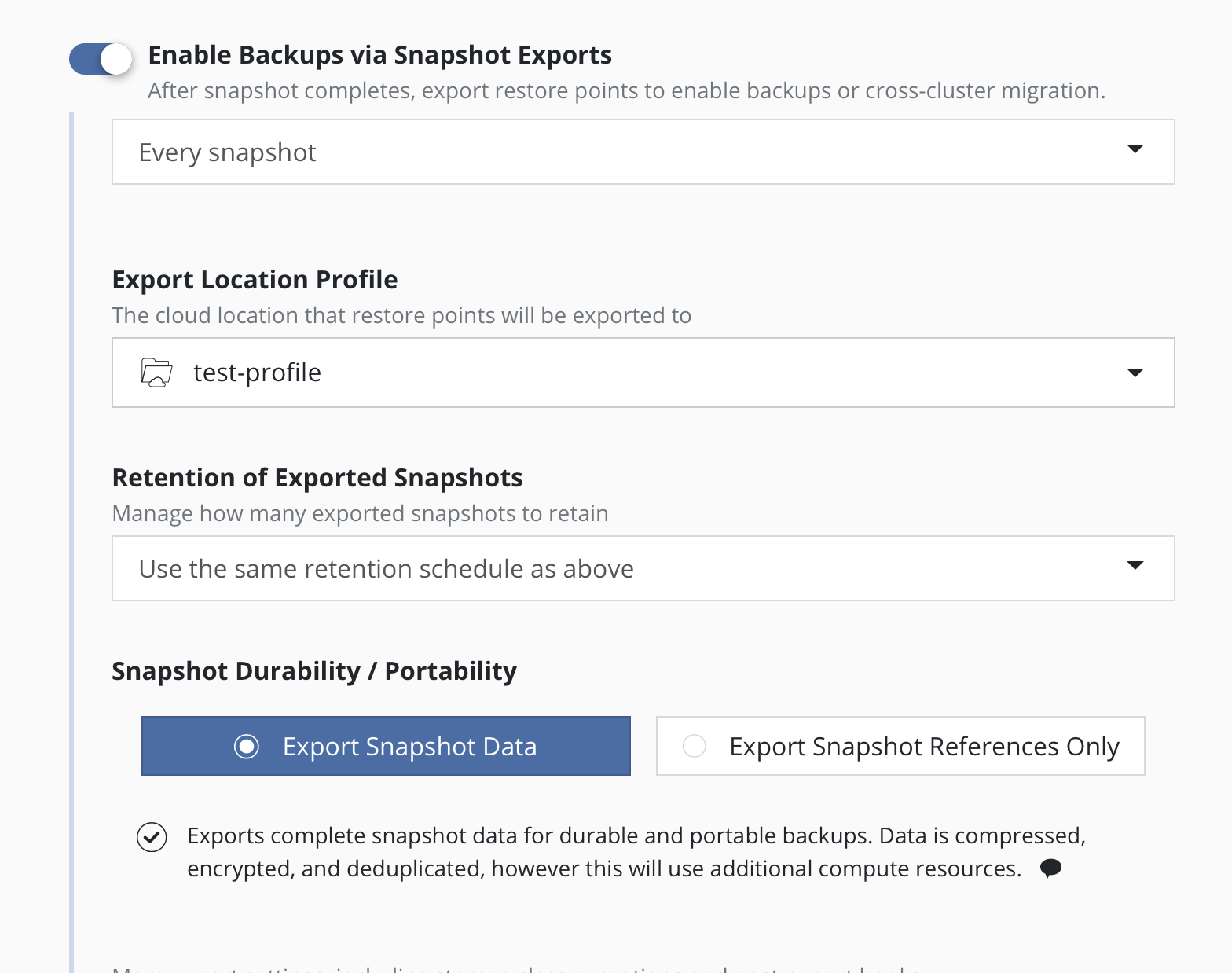
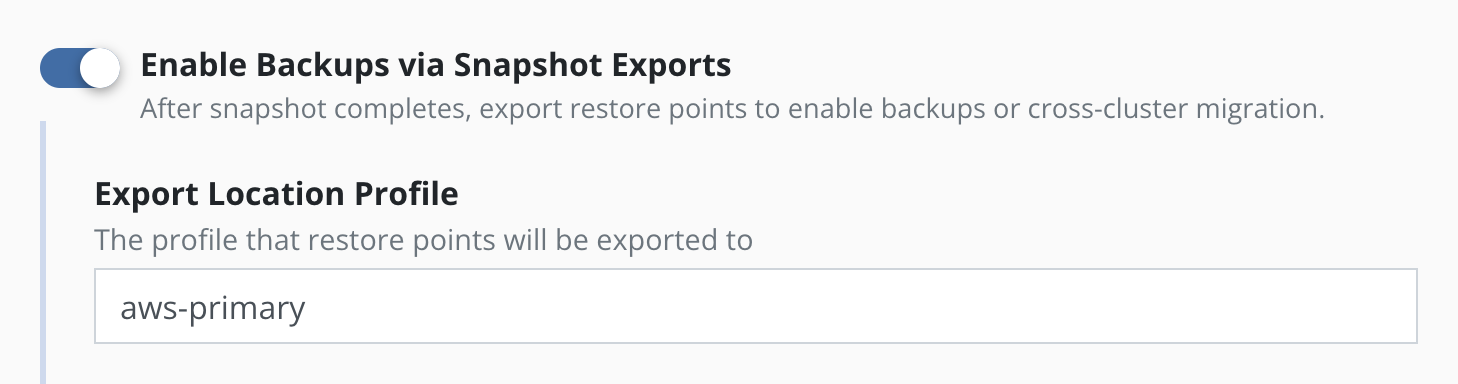
To convert snapshots into
backups, select Enable Backups via Snapshot Exports during policy
creation. Additional settings for the destination location and control
over the export of snapshot data versus just a reference will also be
visible here. These are primarily used for migrating applications across
clusters and more information on them can be found in the
Exporting Applications section. These settings are available when creating a
policy, and when manually exporting a restore point.
The backup produced by an export action consists of metadata of the
application and snapshot data for the application volumes. The
destination for the metadata export is an
Object Storage Location or an
NFS/SMB File Storage Location that is specified in the Export Location Profile field.
There are two options by which Veeam Kasten exports snapshot data: Filesystem Mode Export or Block Mode Export.
Each mechanism defines the process of uploading, downloading, and managing snapshot data in a specific destination location. The default export mechanism is selected automatically on a per-volume basis, based on the Volume Mode used to mount the volume in a Pod:
- The Filesystem Mode Export mechanism is used to export snapshot data of volumes with a Filesystem volume mode.
- The Block Mode Export mechanism is used to export snapshot data of volumes with a Block volume mode.
Additionally, there are scenarios in which Filesystem mode volumes may be exported using the Block Mode Export mechanism. See Block Mode Export for details.
The two export mechanisms are described below:
Filesystem Mode Export
This is the default mode of export for a volume mounted in
Filesystem volume mode. Such volumes are attached via the
volumeMounts property of a Pod container specification.
A filesystem mode export assumes that the format of the data on the application disk is a filesystem. During upload, this export mechanism creates a clone of the source PersistentVolume from the volume snapshot produced by the Veeam Kasten policy. This volume is then mounted in a temporary Pod which deduplicates, compresses, encrypts, and uploads the data to the repository. During restore operations the target volume is similarly mounted in a temporary Pod using filesystem volume mode and the exported data is restored.
Block Mode Export
This is the default mode of export for a volume mounted in Block
volume mode. Such volumes are attached via the volumeDevices property
of a Pod container specification.
A block mode export accesses the content of the disk snapshot at the block level. If changed block tracking (CBT) data is available for the volume and is supported in Veeam Kasten for the provisioner concerned, Veeam Kasten will export the incremental changes to the repository without needing to perform client-side fingerprinting and deduplication. If CBT is unavailable, Veeam Kasten will read the entire source volume upon export in order to produce an incremental backup.
During the export process, the temporary datamover Pod will use provisioner-specific network data transfer APIs to read volume snapshot data, if available and supported by Veeam Kasten. Alternatively, if these APIs are not available, a clone of the source PersistentVolume will be created from the volume snapshot produced by the Veeam Kasten policy. This volume is then mounted in the temporary Pod using Block volume mode, and the data will be read from the raw volume.
Similarly, during the restore process, the mechanism will use storage provisioner specific network data transfer APIs if available and supported by Veeam Kasten, to directly write the data to the target volume. Alternatively, if these APIs are not available, the target volume will be mounted in the temporary Pod using Block volume mode and the data will be written to the raw volume.
When block mode export is used, the organization of exported data is based on the type of location profile configured in the policy:
-
When the destination is an Object Storage Location or an NFS/SMB File Storage Location, snapshot data will be uploaded in a Veeam Kasten specific format which provides deduplication, compression and encryption support in the specified destination.
Automatic compaction will be performed periodically on volume data, to ensure that the chain of incremental backups that follows a full backup will not grow too long. Compaction synthesizes a full backup by applying the chain of incremental backups to the base full backup and saving the result as a new full backup; no block data is uploaded during compaction as only references to data blocks are manipulated by the operation.
Metadata will also be sent to the same destination location, though it is stored separately from the snapshot data.
-
When the destination is a Veeam Repository Location then snapshot data is uploaded to a Veeam Repository in its specific format.
A Veeam Repository Location does not provide metadata storage, which must be specified separately within the policy.
Enabling Block Mode Export
To enable block mode exports and restores, first use the Veeam Kasten Primer Block Mount Check to validate the storage provisioner is compatible with block mode.
Next, apply the following annotation to the StorageClass of any compatible provisioner where block mode export will be required:
$ kubectl annotate storageclass ${STORAGE_CLASS_NAME} k10.kasten.io/sc-supports-block-mode-exports=true
The annotation above is not required for StorageClasses using
the csi.vsphere.vmware.com provisioner.
Exporting Filesystem Volumes in Block Mode
A Filesystem volume normally exported in filesystem mode may be exported in block mode if desired, provided its StorageClass meets the requirements and is annotated as described in Enabling Block Mode Export. To enable this behavior, it is necessary to request it on a per-volume basis by setting one of the following annotations on its PersistentVolumeClaim:
$ kubectl annotate pvc -n ${NAMESPACE} ${PVC_NAME} k10.kasten.io/pvc-export-volume-in-block-mode=preferred
$ kubectl annotate pvc -n ${NAMESPACE} ${PVC_NAME} k10.kasten.io/pvc-export-volume-in-block-mode=force
When the annotation value is set to preferred, it gives priority to
block mode export but has the flexibility to fallback to filesystem mode
export if block mode export cannot be performed. If the annotation value is set to
force, an error will be raised if block mode cannot be
performed.
Configuring Block Mode Export Storage API Use
By default, Veeam Kasten uses provisioner-specific network data transfer APIs for both block mode data upload and download, if available. If there is a need for more precise control over the use of these APIs, you can add one of the following annotations to a volume's StorageClass:
$ kubectl annotate storageclass ${STORAGE_CLASS_NAME} k10.kasten.io/block-mode-uses-storage-api=disable
$ kubectl annotate storageclass ${STORAGE_CLASS_NAME} k10.kasten.io/block-mode-uses-storage-api=download-only
$ kubectl annotate storageclass ${STORAGE_CLASS_NAME} k10.kasten.io/block-mode-uses-storage-api=enable
$ kubectl annotate storageclass ${STORAGE_CLASS_NAME} k10.kasten.io/block-mode-uses-storage-api=upload-only
The annotation above is ignored for StorageClasses using
the csi.vsphere.vmware.com provisioner and network data transfer
APIs are always used.
Configuring Block Mode Export in VMware vSphere
When exporting data
in VMware vSphere environments it is possible to optionally enable the use
of the Block Mode Export mechanism for all of the volume
snapshots created by a policy, regardless of the
Volume
Mode
of each persistent volume.This is the preferred way to export snapshot data
in a cluster with volumes provisioned by the csi.vsphere.vmware.com provisioner.
Additionally, when exporting volume data to a
Veeam Repository Location,
Block Mode Export must
be enabled for all volume snapshots associated with the policy.
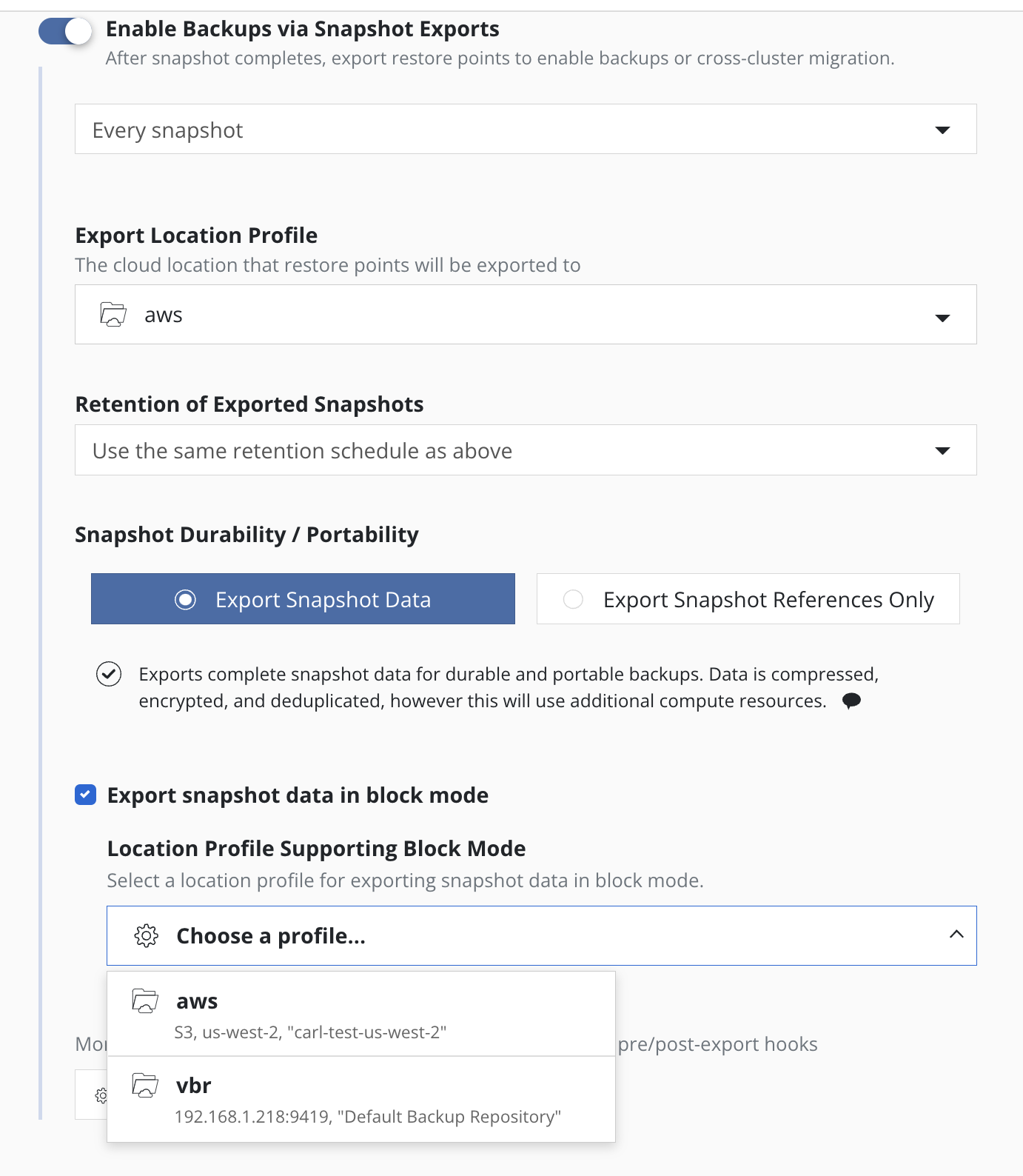
Using the Block Mode Export mechanism for all volume snapshots
is enabled by explicitly selecting the
Export snapshot data in block mode option in the export properties
of the policy and then
selecting an
Object Storage Location, an
NFS/SMB File Storage
or a
Veeam Repository Location profile as the destination for snapshot data in the
Location Profile Supporting Block Mode field.
The location for metadata is specified by the
Export Location Profile field, a required field in the dialog. When
the Location Profile Supporting Block Mode field is an
Object Storage Location or an
NFS/SMB File Storage Location, then both values are required to be the same to
ensure that both metadata and snapshot data are sent to the same
location.
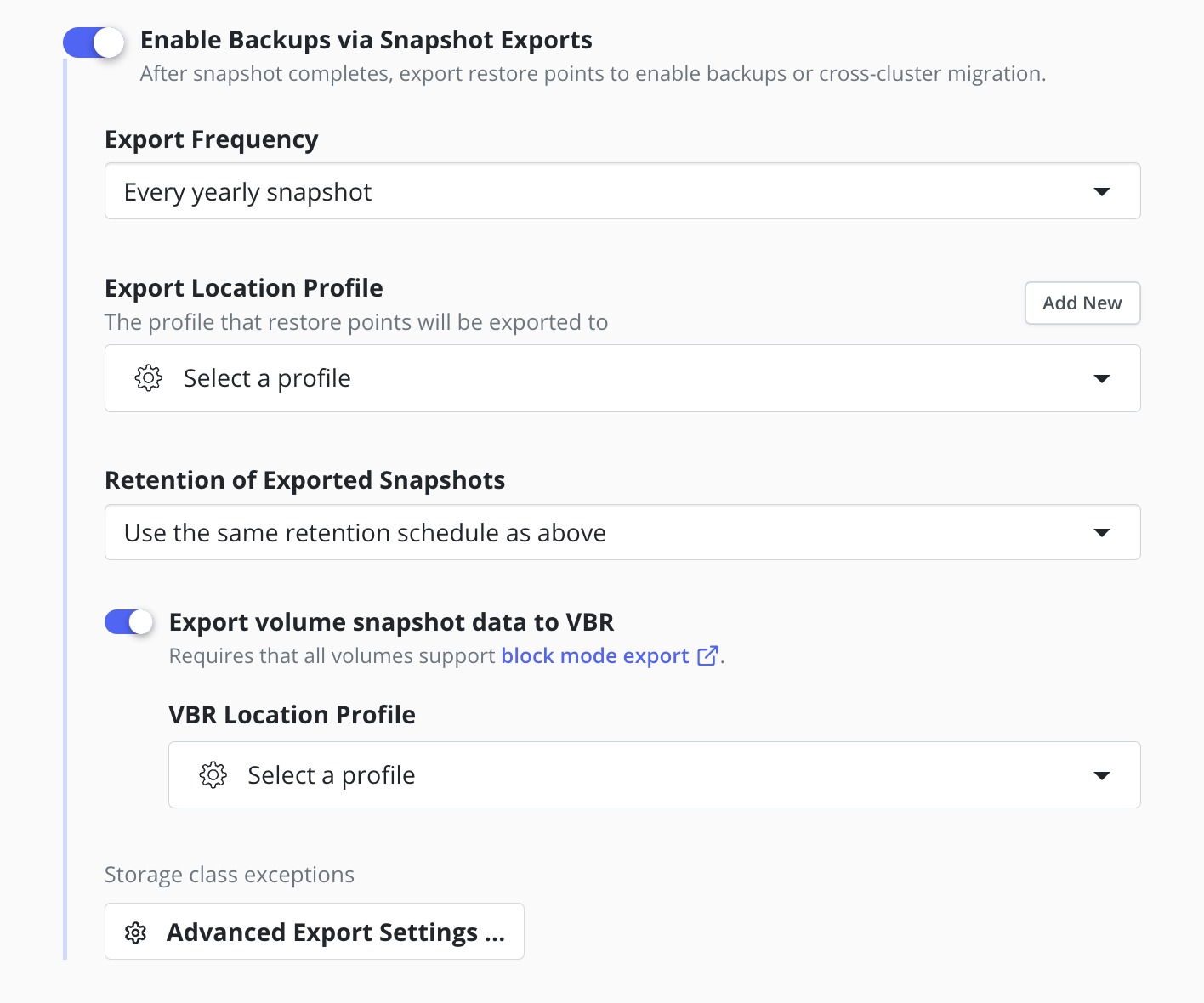
Configuring Block Mode Export to VBR
To export snapshot data to a Veeam Repository Location from a compatible cluster it is required to use the Block Mode Export mechanism for all of the volume snapshots created by a policy, regardless of the Volume Mode of each persistent volume.
First, ensure any required StorageClasses have enabled Block Mode Export.
Using the Block Mode Export mechanism for all volume snapshots
is enabled by explicitly selecting the
Export volume snapshot data to VBR option in the export properties
of the policy and then
selecting an available
Veeam Repository Location profile as the destination.
The location for metadata is specified by the
Export Location Profile field, which requires the selection of a separate
Object Storage Location or an
NFS/SMB File Storage Location.
Scheduling
There are four components to scheduling:
- How frequently the primary snapshot action should be performed
- How often snapshots should be exported into backups
- Retention schedule of snapshots and backups
- When the primary snapshot action should be performed
Action Frequency
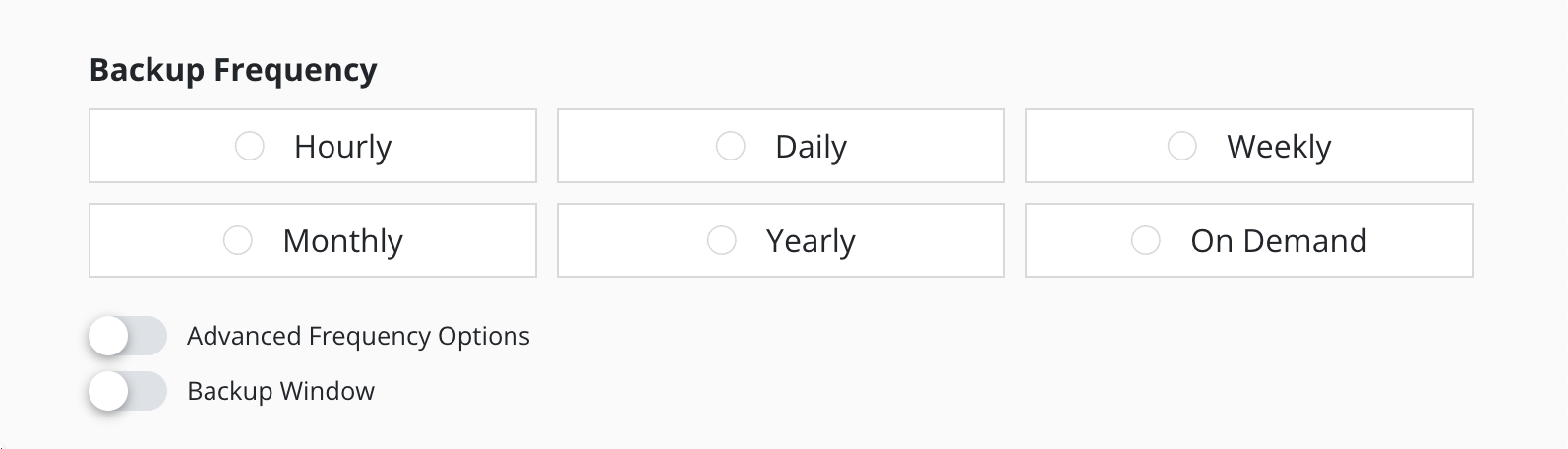
Actions can be set to execute at an hourly, daily, weekly, monthly, or yearly granularity, or on demand. By default, actions set to hourly will execute at the top of the hour and other actions will execute at midnight UTC.
It is also possible to select the time at which scheduled actions will execute and sub-frequencies that execute multiple actions per frequency. See Advanced Schedule Options below.
Sub-hourly actions are useful when you are protecting mostly Kubernetes objects or small data sets. Care should be taken with more general-purpose workloads because of the risk of stressing underlying storage infrastructure or running into storage API rate limits. Further, sub-frequencies will also interact with retention (described below). For example, retaining 24 hourly snapshots at 15-minute intervals would only retain 6 hours of snapshots.
Snapshot Exports to Backups
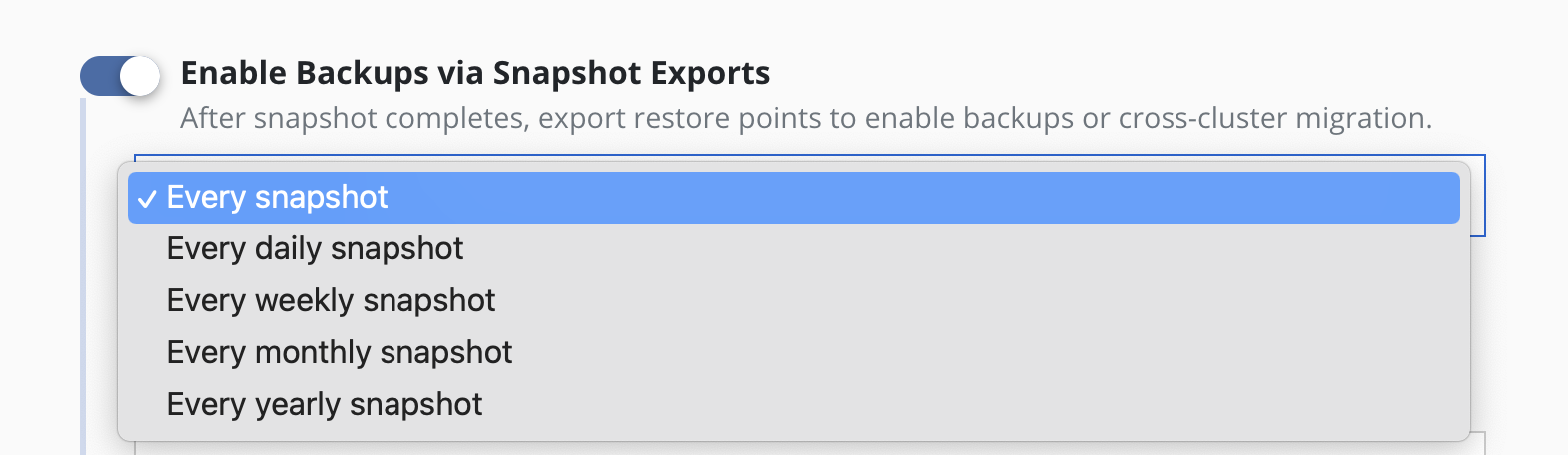
Backups performed via exports, by default, will be set up to export every snapshot into a backup. However, it is also possible to select a subset of snapshots for exports (e.g., only convert every daily snapshot into a backup).
To maintain backup recovery points, once the policy is saved the export location profile can only be changed to a compatible location profile. The UI will enforce compatibility when editing a policy, but no compatibility enforcement is performed when editing the policy CR directly.
Retention Schedules
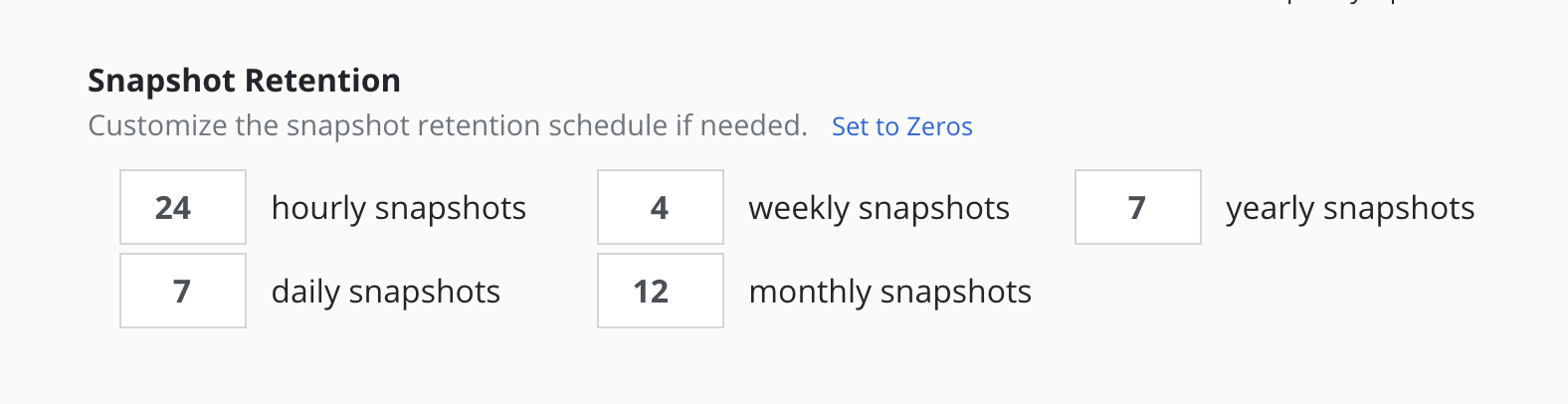
A powerful scheduling feature in Veeam Kasten is the ability to use a GFS retention scheme for cost savings and compliance reasons. With this backup rotation scheme, hourly snapshots and backups are rotated on an hourly basis with one graduating to daily every day and so on. It is possible to set the number of hourly, daily, weekly, monthly, and yearly copies that need to be retained and Veeam Kasten will take care of both cleanup at every retention tier as well as graduation to the next one. For on demand policies it is not possible to set a retention schedule.
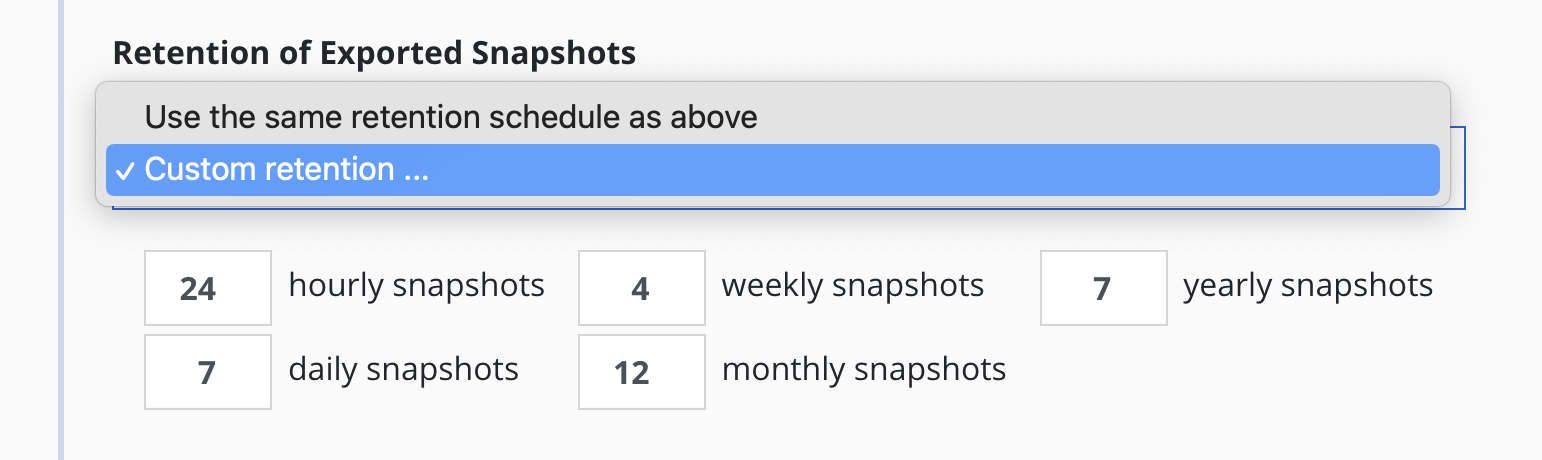
By default, backup retention schedules will be set to be the same as snapshot retention schedules but these can be set to independent schedules if needed. This allows users to create policies where a limited number of snapshots are retained for fast recovery from accidental outages while a larger number of backups will be stored for long-term recovery needs. This separate retention schedule is also valuable when limited number of snapshots are supported on the volume but a larger backup retention count is needed for compliance reasons.
The retention schedule for a policy does not apply to snapshots and backups produced by manual policy runs. Any artifacts created by a manual policy run will need to be manually cleaned up.
Restore points created by failed policy runs do not count towards retiring older restore points and are retained until there are enough newer restore points from successful policy runs to satisfy the retention counts. This situation can arise when policy runs are partially successful, such as when a policy run successfully backs up one app but fails on another or when export fails after successfully creating a local restore point. This outcome can lead to more restore points than expected, as failed policy runs may create restore points until the policy stops failing. If desired, restore points from failed runs can be manually deleted before reaching the point where there are sufficient new successful policy runs to meet the retention counts.
When restore points are retired, whether done manually or through a policy retention schedule, Veeam Kasten takes care of cleaning up the associated resources. The cleanup process is not immediate for all resources; some are removed right away, while others, such as backup data stored in an object store, may take a significant amount of time to be completely removed. Data references shared between restore points, aggregated data awaiting garbage collection, version retention for immutable backups, and safety windows for re-referencing data are among the reasons why retiring a restore point might not immediately free up space in the underlying storage.
Additionally, due to data deduplication, some retirements may result in minimal or no resource usage reclamation. It is important to note that the increase in storage usage when creating a restore point does not reflect the expected space reclamation once the restore point is cleaned up.
Advanced Schedule Options
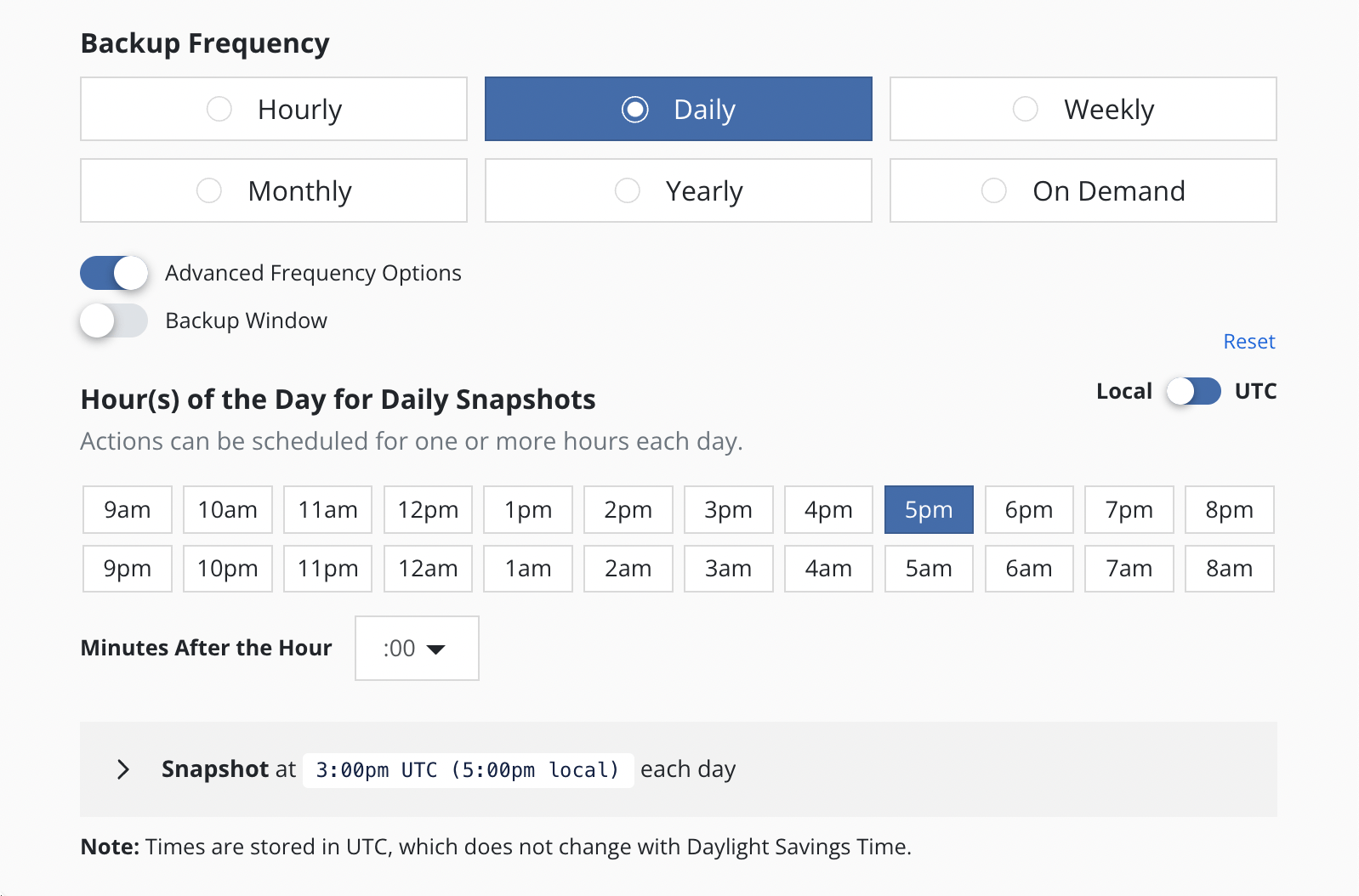
By default, actions set to hourly will execute at the top of the hour and other actions will execute at midnight UTC.
The Advanced Options settings enable picking how many times and when
actions are executed within the interval of the frequency. For example,
for a daily frequency, what hour or hours within each day and what
minute within each hour can be set.
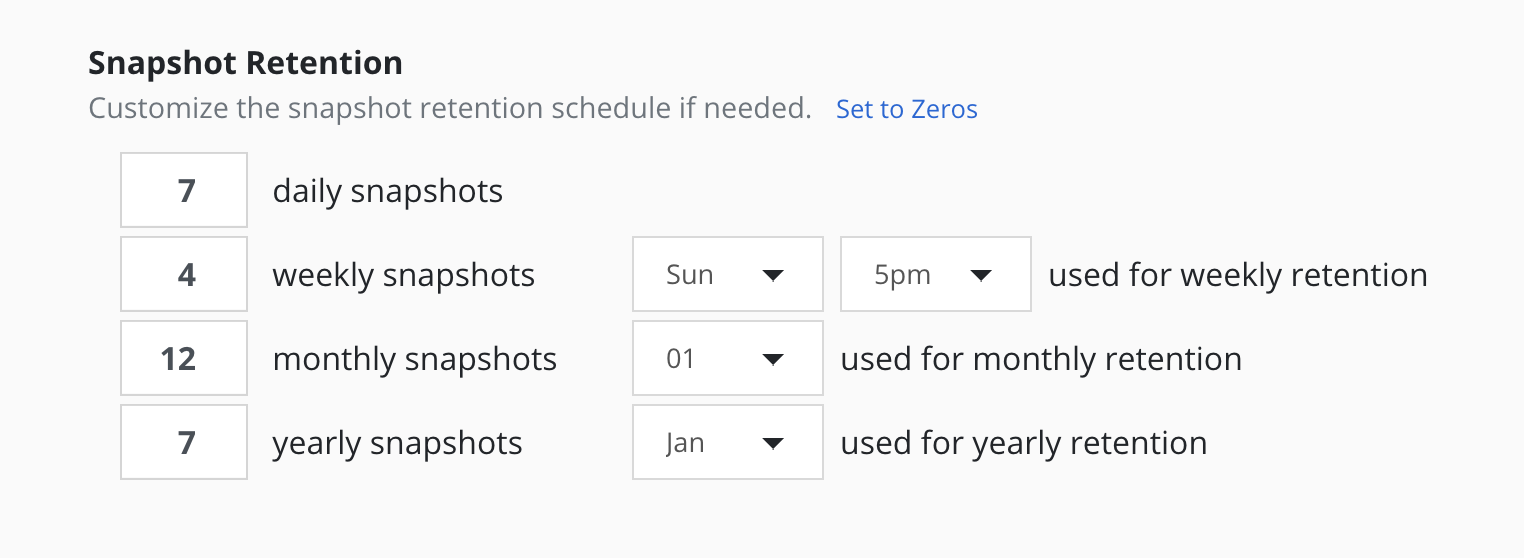
The retention schedule for the policy can be customized to select which snapshots and backups will graduate and be retained according to the longer period retention counts.
By default, hourly retention counts apply to the hourly at the top of the hour, daily retention counts apply to the action at midnight, weekly retention counts refer to midnight Sunday, monthly retention counts refer to midnight on the 1st of each month, and yearly retention counts refer to midnight on the 1st of January (all UTC).
When using sub-frequencies with multiple actions per period, all of the actions are retained according to the retention count for that frequency.
The Advanced Options settings allows a user to display and enter times in either local time or UTC. All times are converted to UTC and Veeam Kasten policy schedules do not change for daylight savings time.
Backup Window
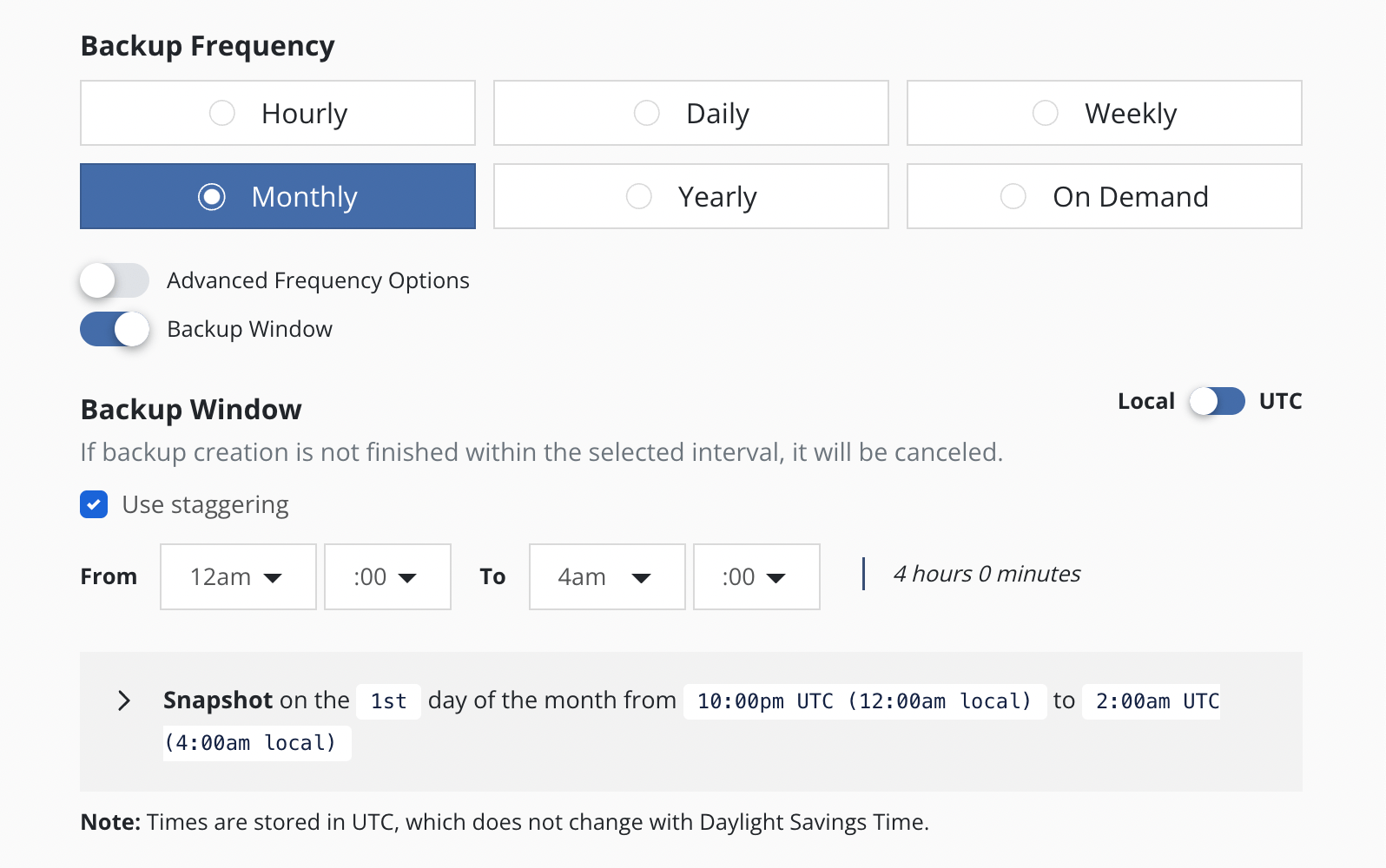
The Backup Window settings allow a user to select a time interval
within which the policy will run. The policy is scheduled to run once at
the Backup Window start time. If the selected time interval is too
short, the policy run will not finish and will be canceled.
If the policy has an hourly frequency and the duration of the Backup Window exceeds 1 hour, the policy is also scheduled to run every 60 minutes thereafter within the Backup Window.
Advanced Frequency Options can be used with Backup Window but with
some limitations. The Backup Window settings override time settings
(hours and minutes) selected in the Advanced Frequency Options. Advanced
Frequency Options are not available for Hourly and Daily frequencies and
only partially available for the other frequency options.
Staggering
With staggering enabled, Veeam Kasten will automatically find an optimal start time and run the policy within the selected interval. Staggering allows Veeam Kasten the flexibility to stagger runs of multiple policies and reduce the peak load on the overall system.
Application Selection and Exceptions
This section describes how policies can be bound to applications, how namespaces can be excluded from policies, how policies can protect cluster-scoped resources, and how exceptions can be handled.
Application Selection
You can select applications by two specific methods:
- Application Names
- Labels
Selecting By Application Name
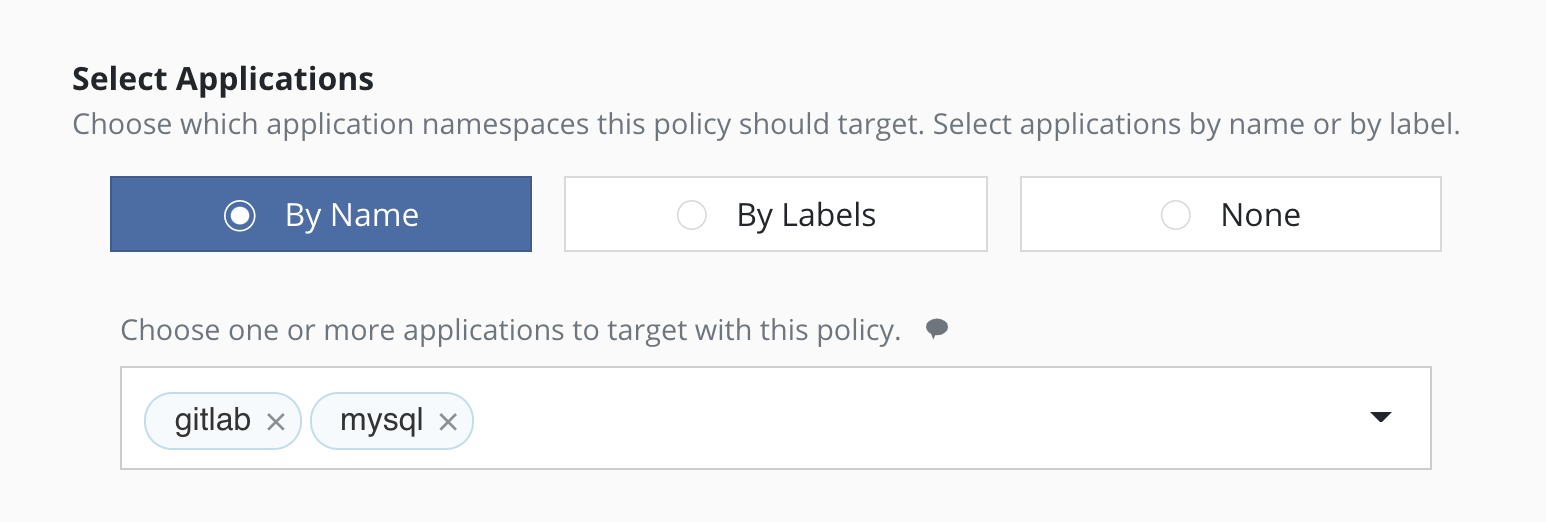
The most straightforward way to apply a policy to an application is to use its name (which is derived from the namespace name). Note that you can select multiple application names in the same policy.
Selecting By Application Name Wildcard
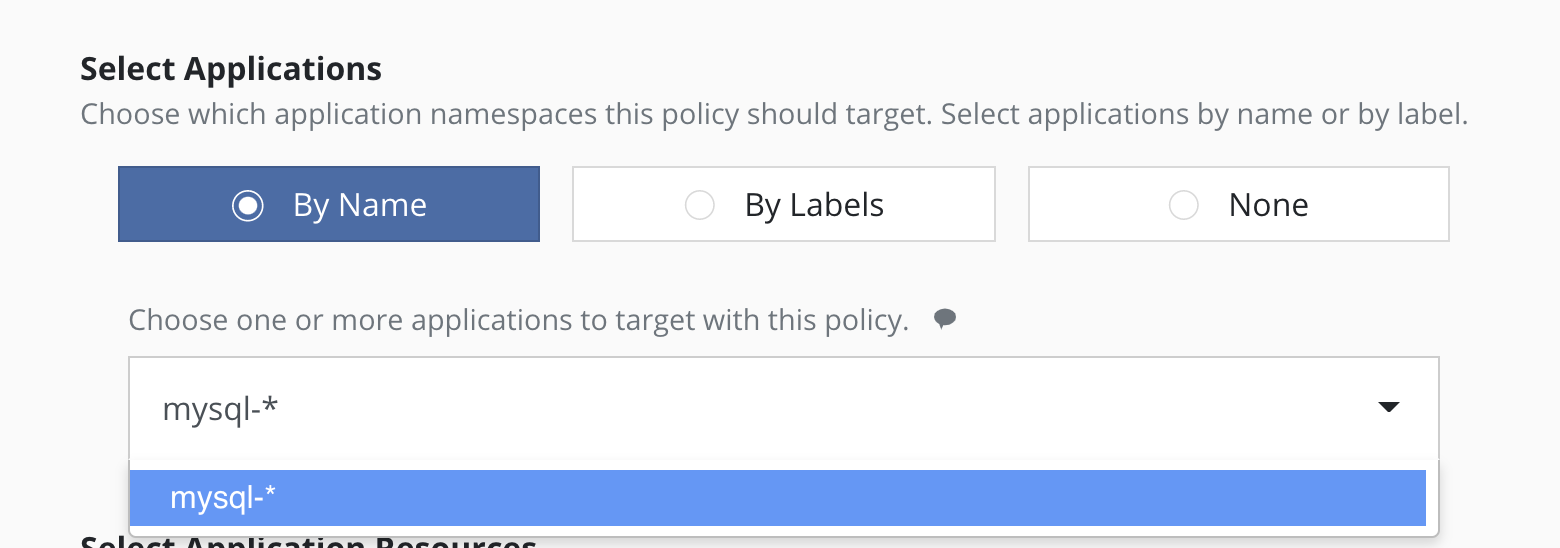
For policies that need to span similar applications, you can select applications by an application name wildcard. Wildcard selection will match all application that start with the wildcard specified.
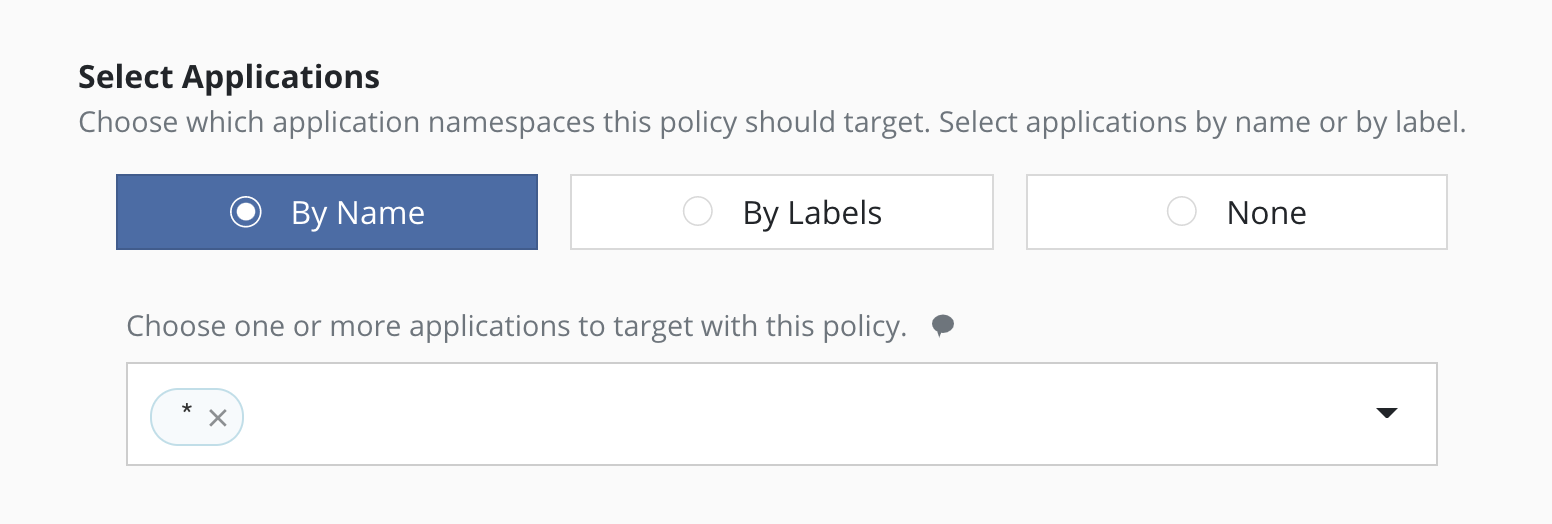
For policies that need to span all applications, you can select all
applications with a * wildcard.
Selecting No Applications
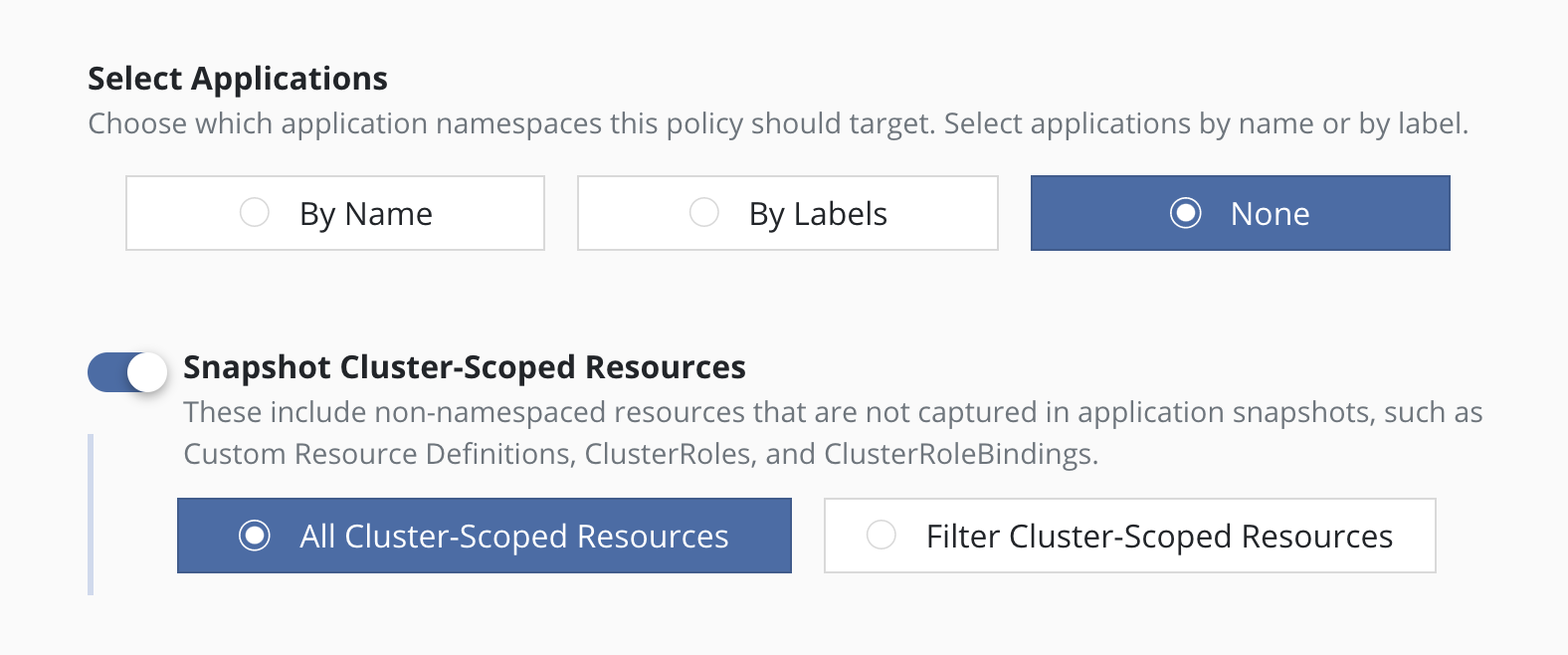
For policies that protect only cluster-scoped resources and do not target any applications, you can select "None". For more information about protecting cluster-scoped resources, see Cluster-Scoped Resources.
Selecting By Labels
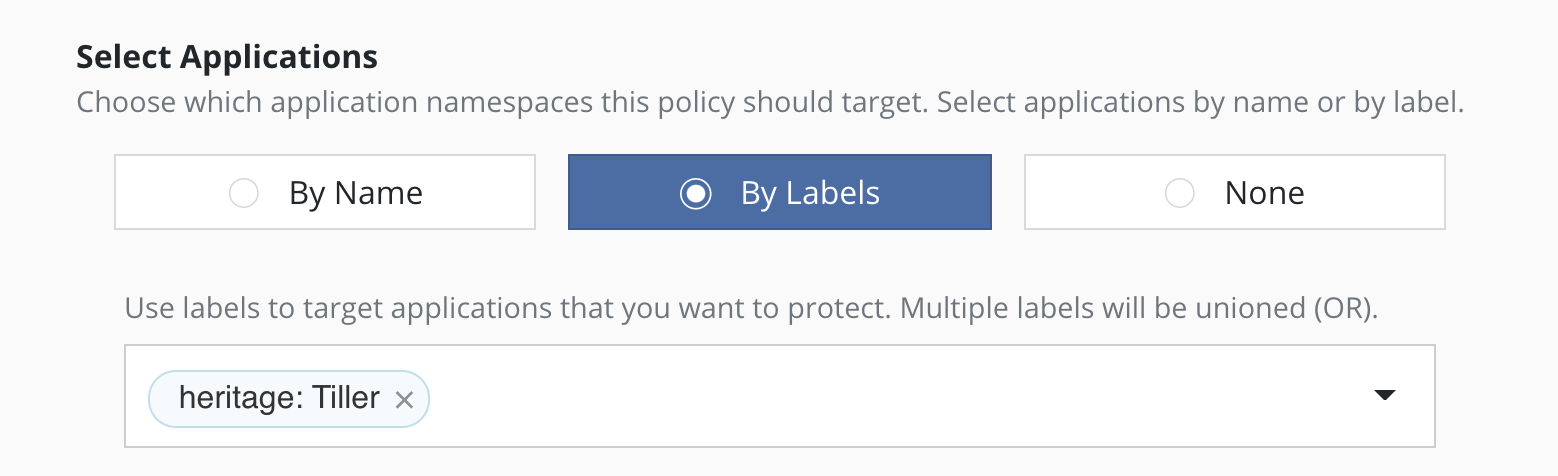
For policies that need to span multiple applications (e.g., protect all applications that use MongoDB or applications that have been annotated with the gold label), you can select applications by label. Any application (namespace) that has a matching label as defined in the policy will be selected. Matching occurs on labels applied to namespaces, deployments, and statefulsets. If multiple labels are selected, a union (logical OR) will be performed when deciding to which applications the policy will be applied. All applications with at least one matching label will be selected.
Note that label-based selection can be used to create forward-looking
policies as the policy will automatically apply to any future
application that has the matching label. For example, using the
heritage: Tiller (Helm v2) or heritage: Helm (Helm v3) selector will
apply the policy you are creating to any new Helm-deployed
applications as the Helm package manager automatically adds that label
to any Kubernetes workload it creates.
Namespace Exclusion
Even if a namespace is covered by a policy, it is possible to have the
namespace be ignored by the policy. You can add the
k10.kasten.io/ignorebackuppolicy annotation to the namespace(s) you
want to be ignored. Namespaces that are tagged with the
k10.kasten.io/ignorebackuppolicy annotation will be skipped during
scheduled backup operations.
Exceptions
Normally Veeam Kasten retries when errors occur and then fails the action or policy run if errors persist. In some circumstances it is desirable to treat errors as exceptions and continue the action if possible.
Examples of when Veeam Kasten does this automatically include:
-
When a Snapshot policy selects multiple applications by label and
creates durable backups by exporting snapshots, Veeam Kasten treats
failures across applications independently.
- If the snapshot for an application fails after all retries, that application is not exported. If snapshots for some applications succeed and snapshots for other applications fail, the failures are reported as exceptions in the policy run. If snapshots for all applications fail, the policy run fails and the export is skipped.
- If the export of a snapshot for an application fails after retries, that application is not exported. If the export of snapshots for some applications succeed and others fail, the failures are reported as exceptions in the export action and policy run. If no application is successfully exported, the export action and policy run fail.
In some cases, treating errors as exceptions is optional:

- Veeam Kasten normally waits for workloads (e.g., Deployments or StatefulSets) to become ready before taking snapshots and fails the action if a workload does not become ready after retries. In some cases the desired path for a backup action or policy might be to ignore such timeouts and to proceed to capture whatever it can in a best-effort manner and store that as a restore point.
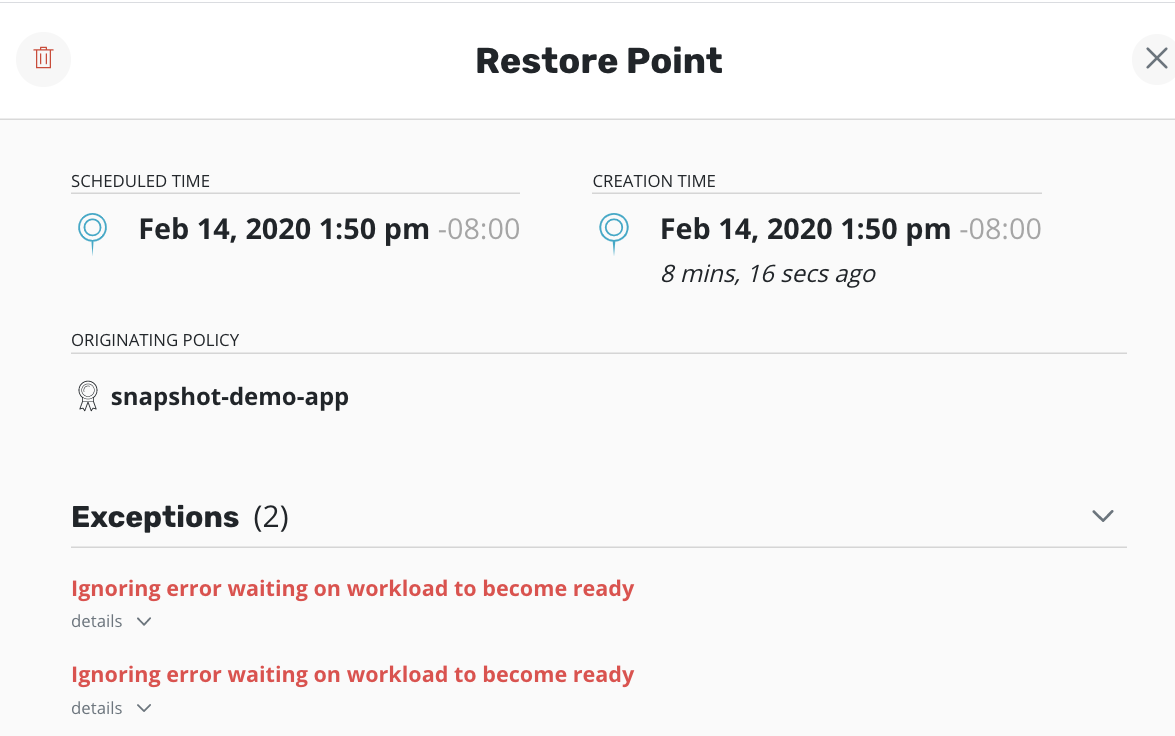
When an exception occurs, the job will be completed with exception(s):

Details of the exceptions can be seen with job details:
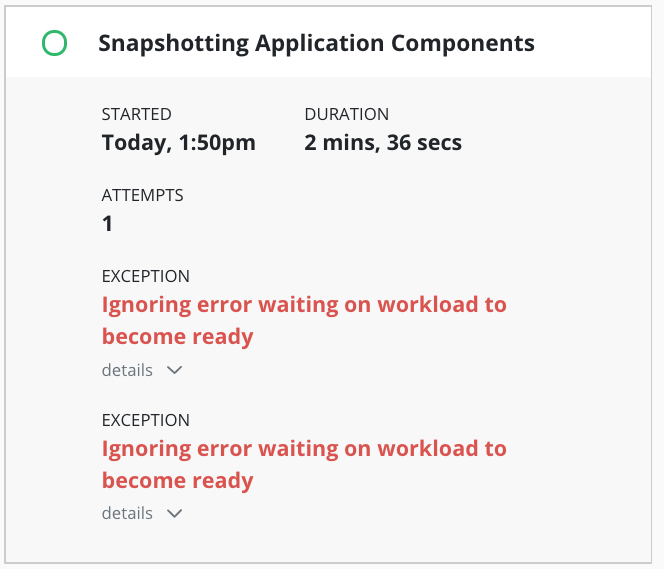
Any exception(s) ignored when creating a restore point are noted in the restore point:
Resource Filtering
This section describes how specific application resources can either be included or excluded from capture or restoration.
Filters should be used with care. It is easy to accidentally define a policy that might leave out essential components of your application.
Resource filtering is supported for both backup and restore operations, whether performed through policies or manual actions. Separate resource filters can be specified for namespaced application resources and cluster-scoped resources. The recommended best practice is to create backup policies that capture all resources to future-proof restores and to use filters to limit what is restored.
In Veeam Kasten, filters describe which Kubernetes resources should be included or excluded in the backup. Backup operations without filters capture the default sets of API resources. Restore operations without filters restore all artifacts from the restore point or cluster restore point.
In an include filter, an entry that specifies only resource names or labels will match the resource types that are included by default. In an exclude filter, such entries apply to all resources selected by the include filter or by default.
Filtering Resources by GVRN
Resource types are identified by group, version, and resource type
names, or
GVR
(e.g., networking.k8s.io/v1/networkpolicies). Individual resources are
identified by their resource type and resource name, or GVRN.
In a filter, an empty or omitted group, version, resource type or
resource name matches any value. For example, if you set Group: apps
and Resource: deployments, it will capture all Deployments no matter
the API Version (e.g., v1 or v1beta1). Core Kubernetes types do not
have a group name and are identified by just a version and resource type
name (e.g., v1/configmaps). The sentinel value core can be used in
the group field of a filter to match the empty group and not all group
values.
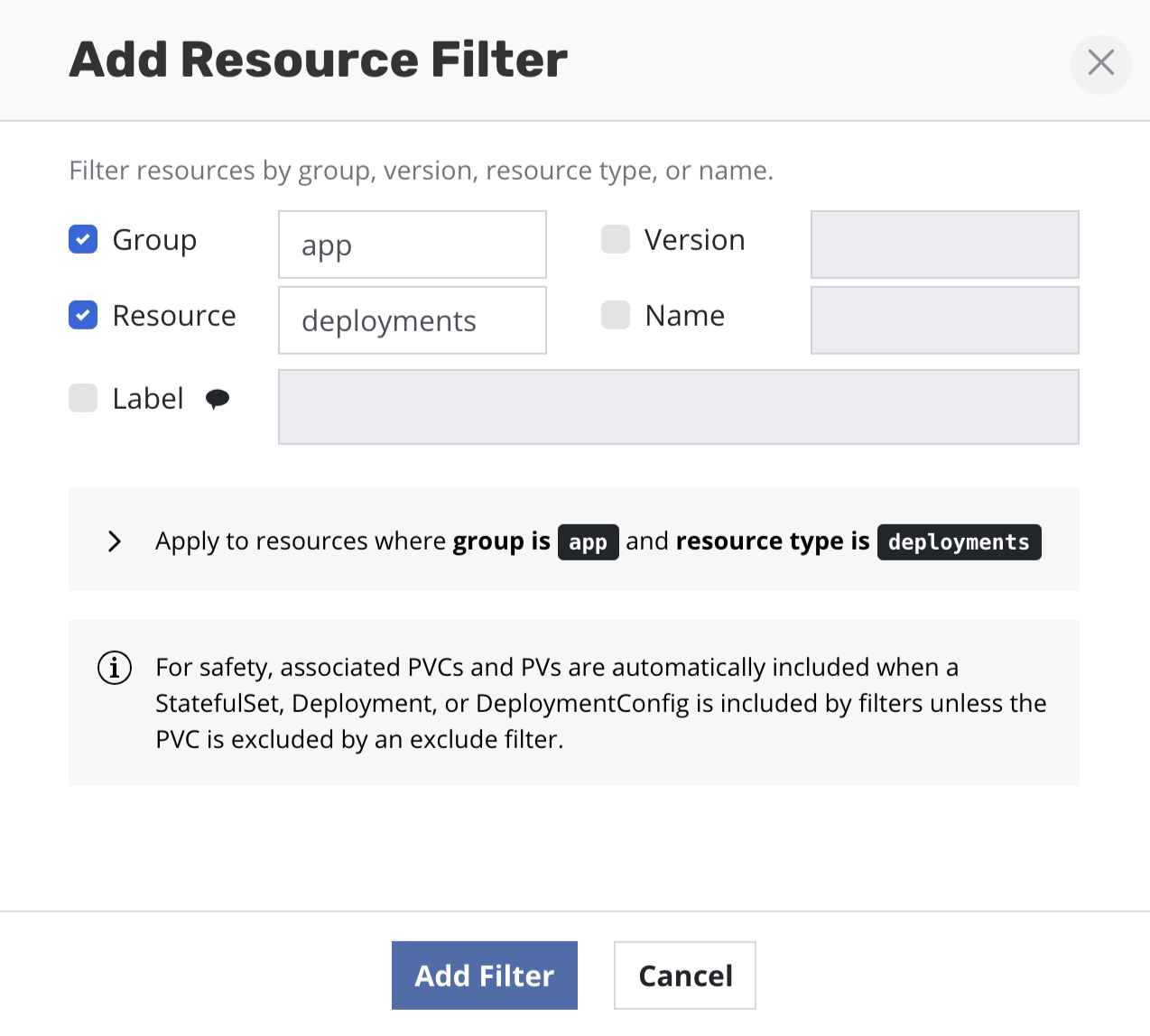
Filters reduce the resources in the backup by first selectively including and then excluding resources:
- If no include or exclude filters are specified, the default API resources belonging to an application are included in the set of resources to be backed up
- If only include filters are specified, resources matching any GVRN entry in the include filter are included in the set of resources to be backed up
- If only exclude filters are specified, resources matching any GVRN entry in the exclude filter are excluded from the default set of resources to be backed up
- If both include and exclude filters are specified, the include filters are applied first and then exclude filters will be applied only on the GVRN resources selected by the include filter
For a full list of API resources in your cluster, run
kubectl api-resources.
Filtering Resources by Labels
Veeam Kasten also supports filtering resources by labels when taking a backup. This is particularly useful when there are multiple apps running in a single namespace. By leveraging label filters, it is possible to selectively choose which application to backup.
The snapshot creation process completes without generating output artifacts if all the resources are deselected. Attempting to export the snapshot fails with the error message "No artifacts provided." For instance, if no resources are selected during label-based filtering, the snapshot process will complete successfully without generating any artifacts. However, the export process will fail. Therefore, for a successful export, including at least one resource is crucial when creating a snapshot.
The rules from the previous section describing the use of include and exclude filters apply to label filters as well.
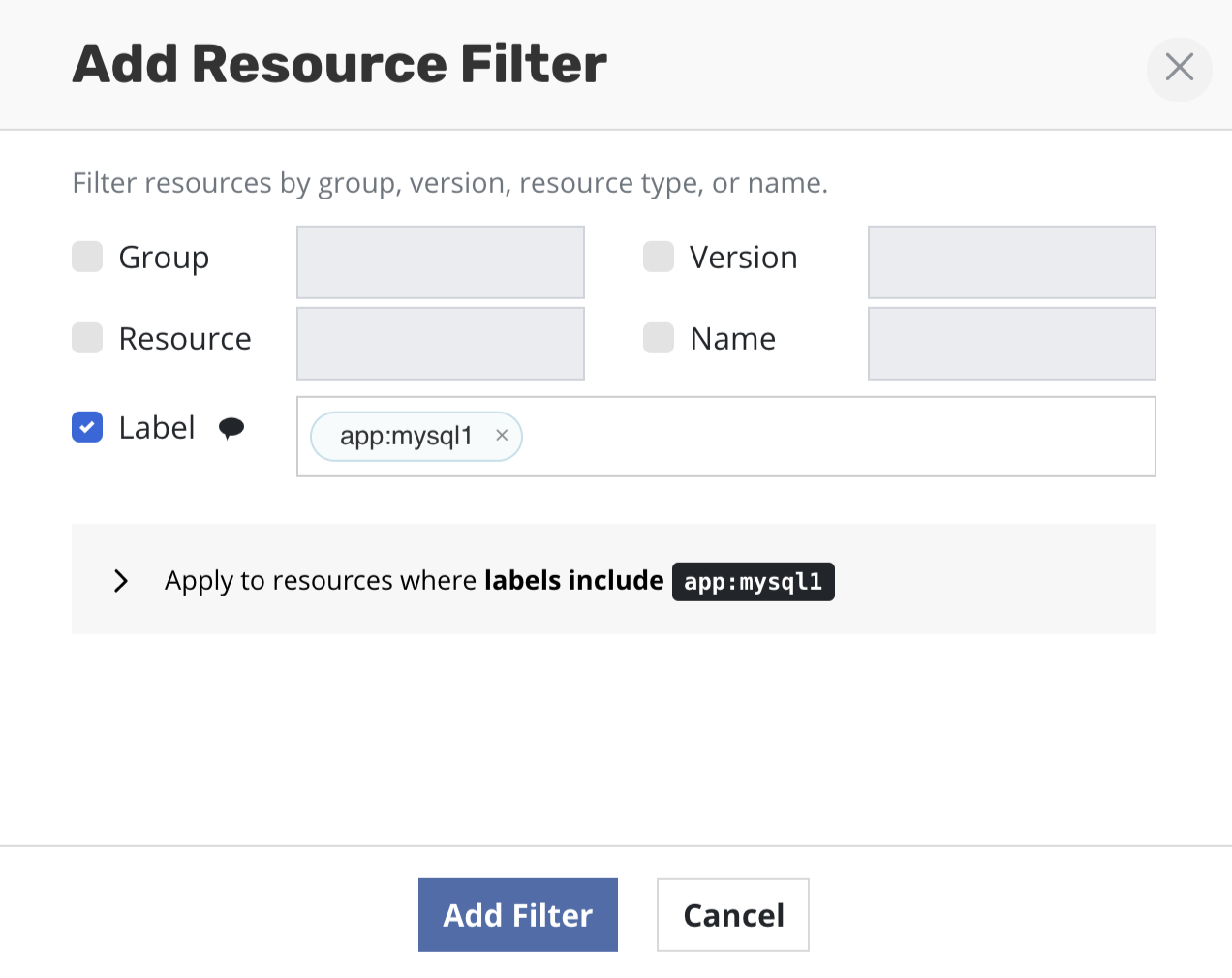
Multiple labels can be provided as part of the same filter if they are intended to be applied together. Conversely, multiple filters, each with their own label, can be provided together, signifying that any of the labels should match.
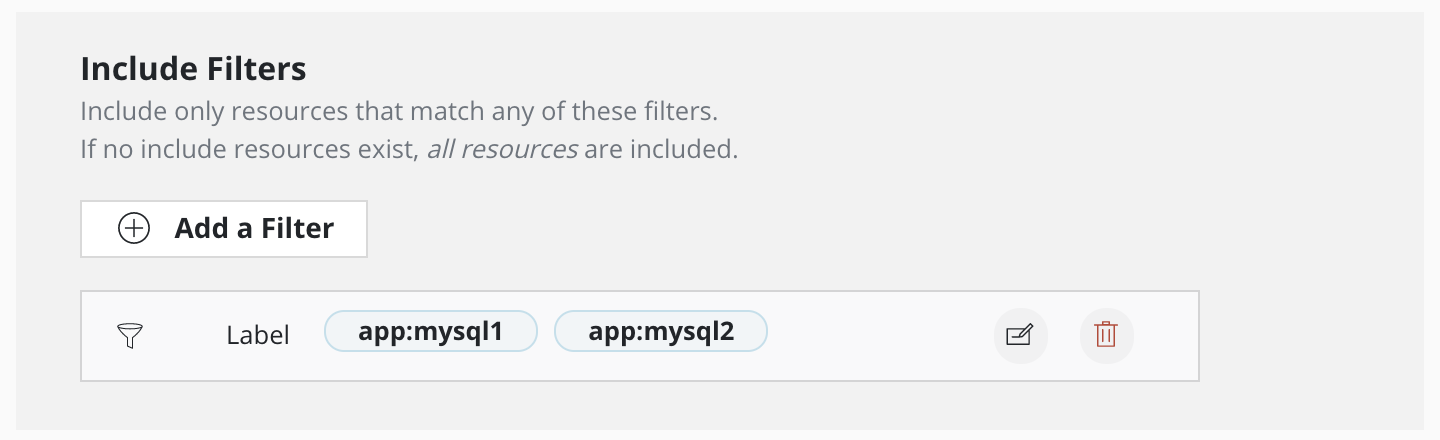
This filter includes resources with either app:mysql2 or app:mysql1 label
This filter includes resources with either app:mysql2 or app:mysql1 label
A filter can specify both GVRN and labels. Such filters match resources that satisfy both the GVRN and the specified labels.
Filter Defaults
Veeam Kasten implements useful defaults for resources included without filters, along with the ability to override and extend those defaults. There are different defaults for namespaced and cluster-scoped resources.
Veeam Kasten considers a Kubernetes namespace similarly to a namespaced object. By default, Veeam Kasten creates a namespace artifact as part of the application backup, and the namespace artifact is stored in a restore point, not a cluster restore point. Filters for application backup and restore can include or exclude the namespace artifact. This differs from namepace exclusion.
The default for backing up namespaced Kubernetes resources is to include:
-
In-tree Kubernetes resources relating to the deployment of
applications.
-
For example, this includes, but is not limited to, specs for
namespaces, workloads (deployments,statefulsets, standalonepods),services,configmaps,secrets,PVCs,serviceaccounts, and more. -
This excludes dynamically-created and low-level resources
relating to the running of applications. Resources such as
endpoints,events,replicasets,metrics,horizontalpodautoscalers, andvolumesnapshotsare not included by default.
-
For example, this includes, but is not limited to, specs for
-
Specific OpenShift resource types:
deploymentconfigs,buildconfigs,imagestreams,imagestreamtags,routes, andtemplates. -
Other custom resource types defined by installed
customresourcedefinitions.
The default for backing up cluster-scoped Kubernetes resources is to include:
storageclassesfrom groupstorage.k8s.iocustomresourcedefinitionsfrom groupapiextensions.k8s.ioclusterrolesfrom grouprbac.authorization.k8s.ioclusterrolebindingsfrom grouprbac.authorization.k8s.io
Resource types that are not backed up by default can be included by
adding them to a GVRN entry in the include filter. Once an include
filter is specified, only resources that match a GVRN entry in the
include filter are included in the set of resources to be backed up. To
include additional resource types plus default resource types,
include a GVRN entry for the defaults resource in the group
actions.kio.kasten.io.
Safe Backup
For safety, Veeam Kasten automatically includes resources such as associated volumes (PVCs and PVs) when a StatefulSet, Deployment, DeploymentConfig, Pod, or Virtual Machine workload is included by filters. Such auto-included resources can be omitted by specifying an exclude filter.
Filter Examples
This table illustrates the use of filters when backing up an application:
| Include Filter | Exclude Filter | Captured in Restore Point |
|---|---|---|
| none | none | All default resources |
{Group: core, Resource: configmaps} |
{Label: app:otherapp} |
All configmaps except for any with label app:otherapp |
{Label: app:my-app} |
none | All default resources with the label app:my-app |
{Group: "", Resource: deployments, Name: my-app} |
none | my-app deployment and its PVCs and volume snapshots, if any (Safe Backup) |
{Group: "", Resource: deployment, Name: my-app} |
{Resource: persistentvolumeclaims} |
my-app deployment spec only, no PVCs or volume snapshots |
{Group: autoscaling, Resource: horizontalpodautoscalers} |
none | Any horizontalpodautoscalers (not included by default) |
{Group: autoscaling, Resource: horizontalpodautoscalers}, {Group: actions.kio.kasten.io, Resource: defaults} |
none | All default resources plus any horizontalpodautoscalers |
This table illustrates the use of filters when backing up cluster-scoped resources:
| Include Filter | Exclude Filter | Captured in Cluster Restore Point |
|---|---|---|
| none | none | All default cluster-scoped resources (storageclasses, customresourcedefinitions, clusterroles, clusterrolebindings) |
{Group: storage.k8s.io, Resource: storageclasses} |
none | All storageclasses |
| none | {Resource: clusterrolebindings} |
All default cluster-scoped resources except clusterrolebindings |
{Group: admissionregistration, Resource: mutatingwebhookconfigurations}, {Group: actions.kio.kasten.io, Resource: defaults} |
none | All default cluster-scoped resources plus any mutatingwebhookconfigurations in cluster |
Working With Policies
Using Policy Presets
Operations teams can define multiple protection policy presets that specify parameters such as schedule, retention, location and infrastructure. A catalog of organizational policy presets and SLAs can be provided to the development teams with an intimate knowledge of application requirements, without disclosing credential and storage infrastructure implementation. This ensures separations of concerns while scaling operations in a cloud-native environment.
To create a policy preset, navigate to the Presets page under the
Policies menu in the navigation sidebar. Then simply click
Create New Preset and, as shown below, the policy preset creation
section will be shown.
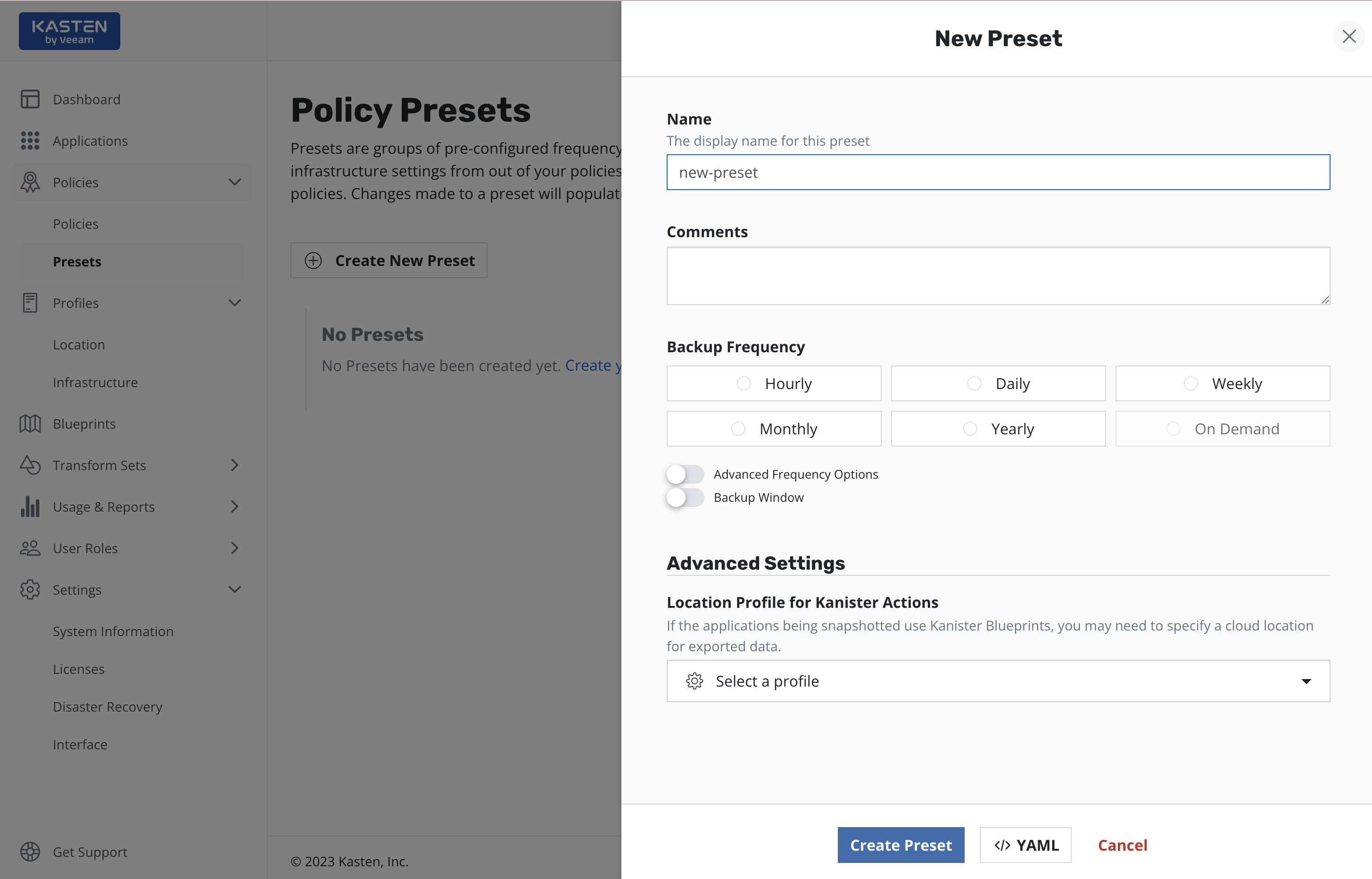
As can be seen, the workflow of the policy preset creation is quite similar to the policy creation. The major difference here is that the policy preset does not contain any application specific settings, which must be specified directly in the policy.
While creating (or editing) a policy the user can opt in to "Use a Preset". Users without list permissions on policy presets can manually enter the name of the policy preset to use, if they have been given that information.
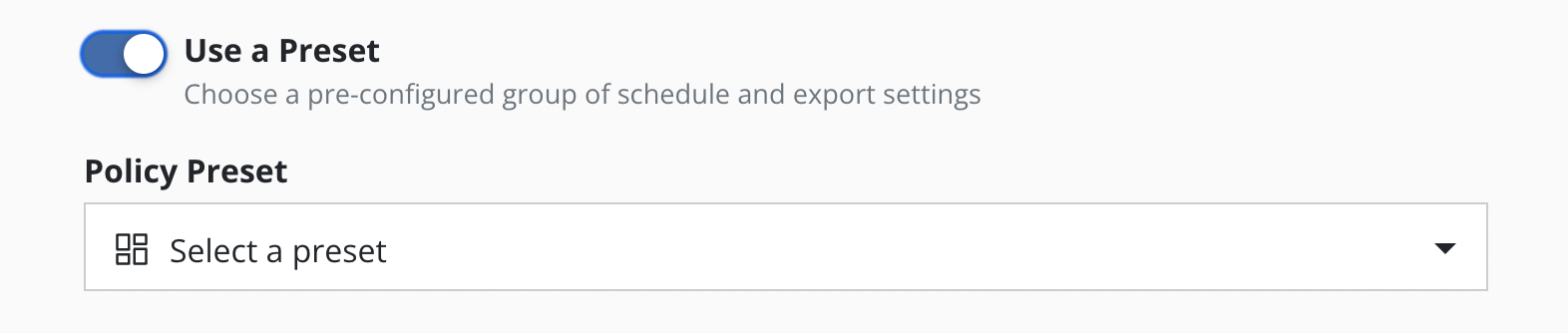
Each policy created using a preset does not copy its configuration but refers to it. This means that every preset change also entails a change in the corresponding policies.
Viewing Policy Activity
After creating a policy and navigating back to the dashboard, the application status is updated from Unmanaged to Non-Compliant, indicating a policy exists but has not successfully run within the specified frequency. This status will change to Compliant upon successful completion of a scheduled or manual run of the policy. The page will now look similar to this:
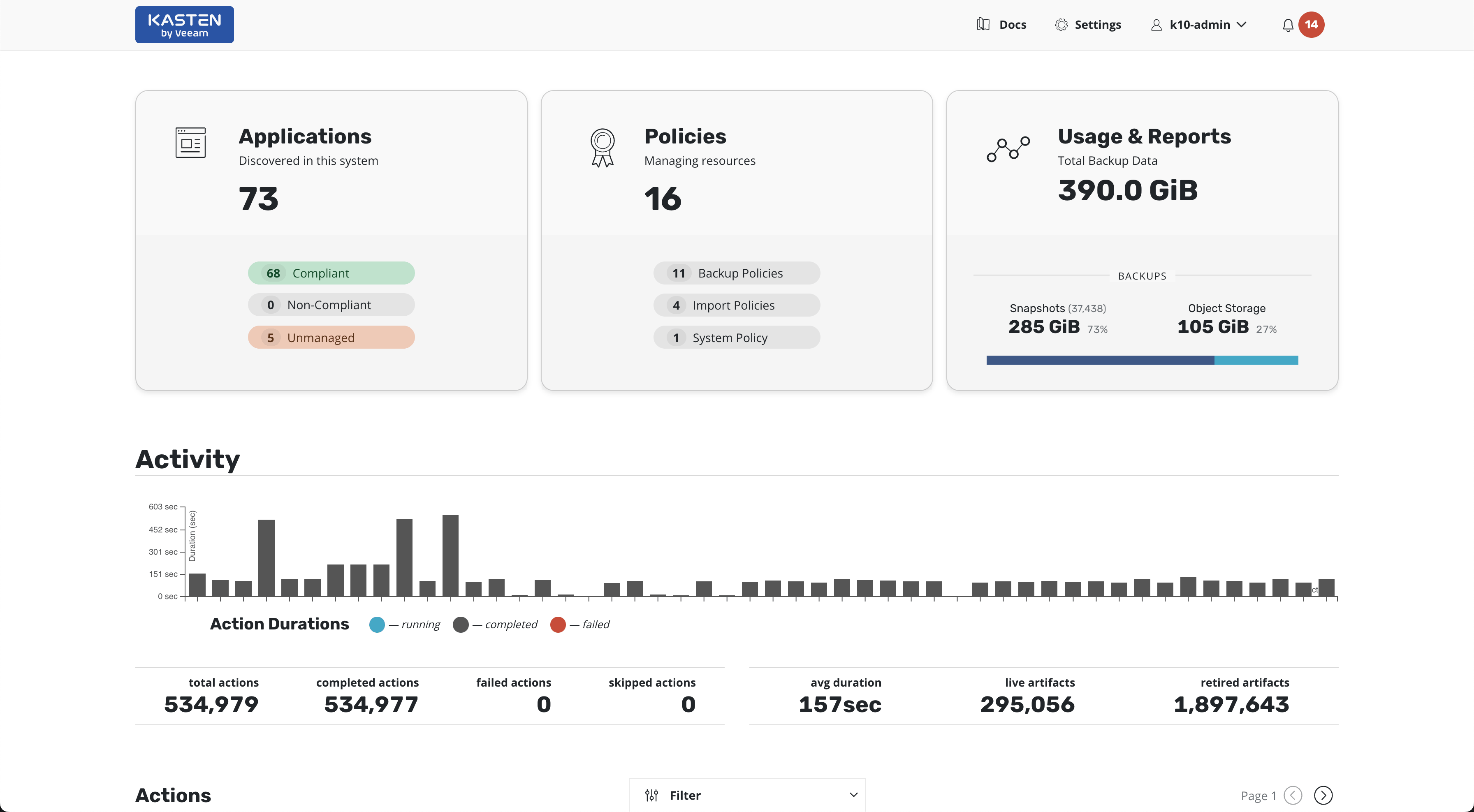
Scrolling down on the page provides visibility into individual action activity. More detailed information can be obtained by clicking on the in-progress or completed jobs.
Manual Policy Runs
It is possible to manually run a policy by going to the Policies page and clicking the Run Once menu option on the desired policy. Note that
unless an expiration time is specified, any artifacts created by this action will not be eligible for automatic retirement and will need to be manually removed.
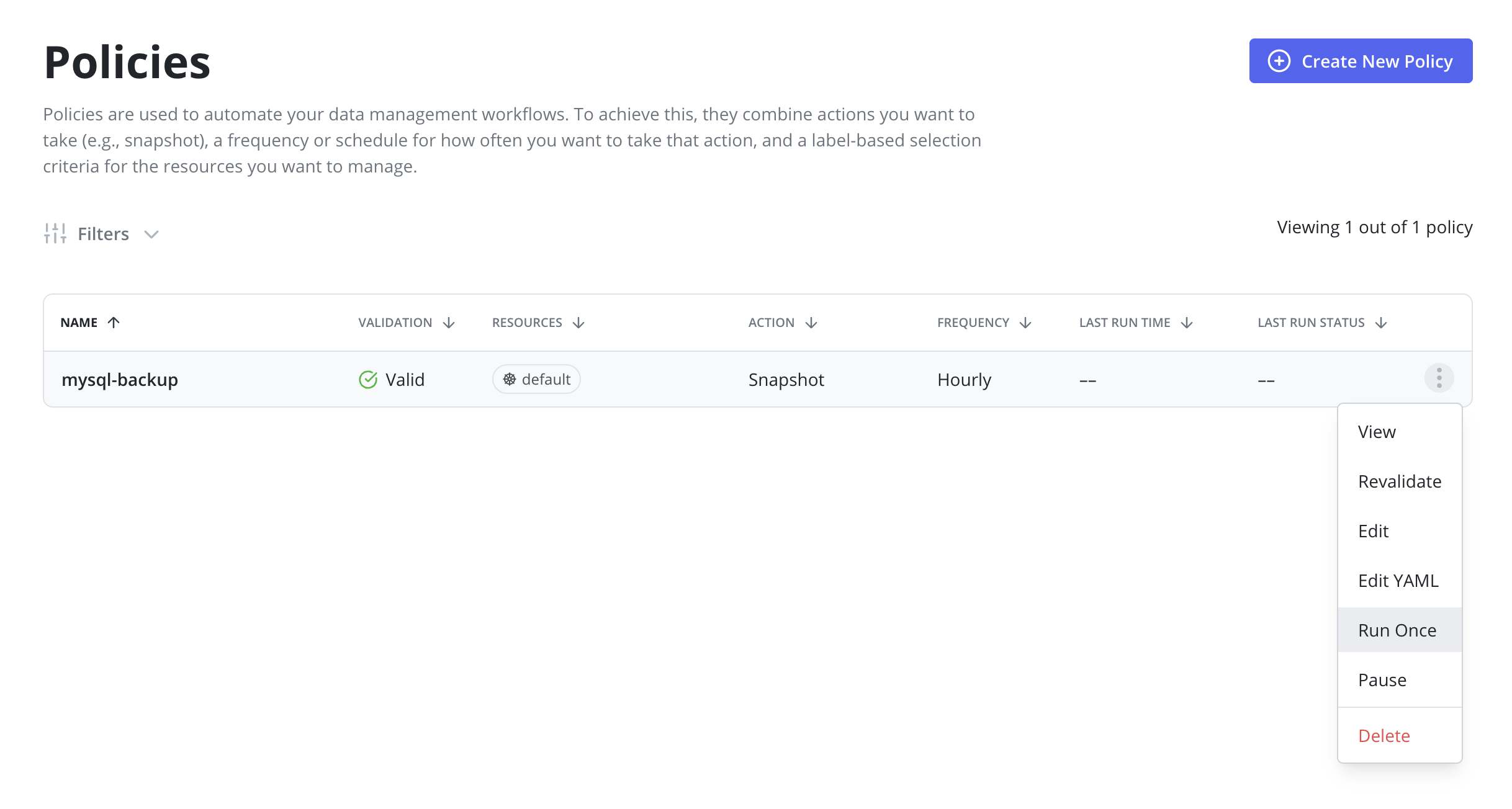
It is also possible to run a policy manually on the Policy View page. First, navigate to the Policy View page by clicking on the policy row or clicking the View menu option on the desired policy. Then, click the Run Once button on the Policy View page.
Pausing Policies
It is possible to pause new scheduled runs of a policy by going to the Policies page
and clicking the Pause menu option on the desired policy.
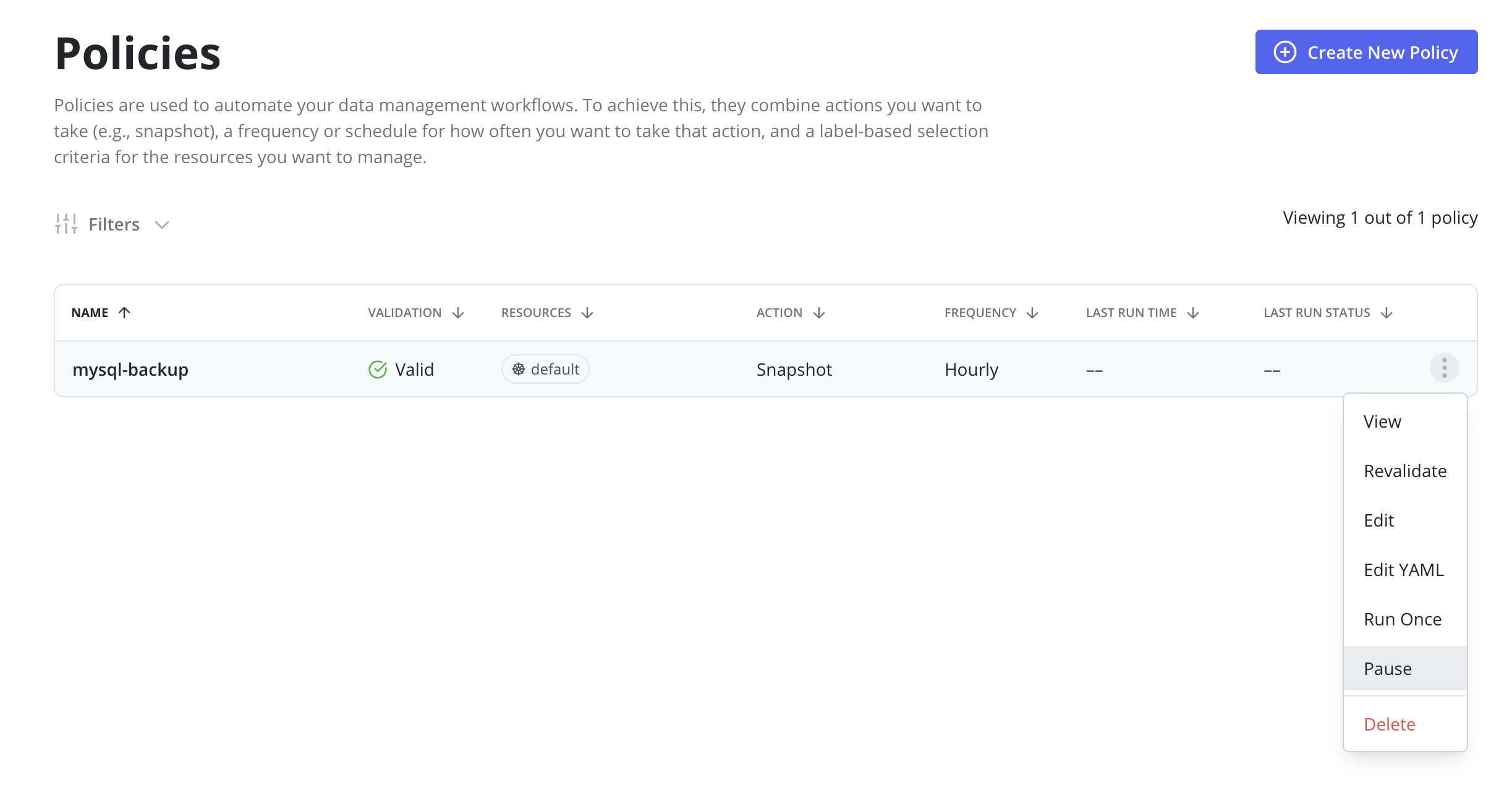
Once a policy is paused, it can be resumed by clicking the Resume menu option on the desired policy. Resuming a policy will allow begin running on it's scheduled frequency again.
Policies can also be paused and resumed from the Policy View page. First, navigate to the Policy View page by clicking on the policy row or clicking the View menu option on the desired policy. Then, click the Pause or Resume button on the Policy View page.
Paused policies do not generate skipped jobs and are ignored for the purposes of compliance. Applications that are only protected by paused policies are marked as unmanaged.
Revalidating Policies
Revalidation is useful when a Policy becomes invalid. Policies that are
invalid will not run and can result in a breach of compliance. To revalidate a policy, go to the Policies page and click the Revalidate menu option on the desired policy.
Editing Policies
Editing a policy is possible from the Policies page using the Edit menu option, or from the Policy View page by clicking the Edit button. This opens a dialog to modify the schedule, retention, and other configuration details.
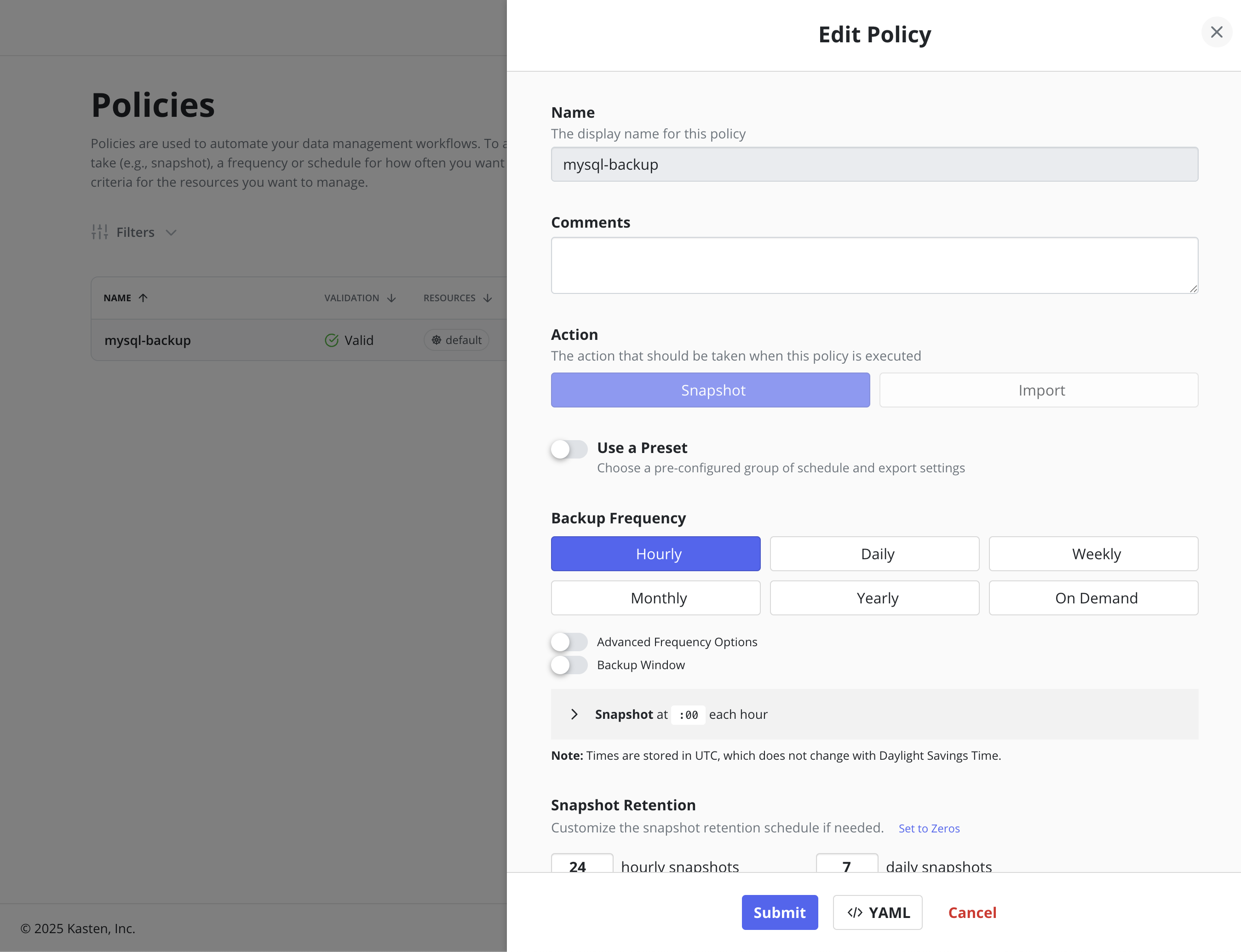
Policies, a Kubernetes Custom Resource (CR), can also be edited directly by manually modifying the CR's YAML through the dashboard or command line.
Changes made to the policy (e.g., new labels added or resource filtering applied) will take effect during the next scheduled policy run.
Careful attention should be paid to changing a policy's retention schedule as that action will automatically retire and delete restore points that no longer fall under the new retention scheme.
Editing retention counts can change the number of restore points retained at each tier during the next scheduled policy run. The retention counts at the start of a policy run apply to all restore points created by the policy, including those created when the policy had different retention counts. Editing Advanced Schedule Options can change when a policy runs in the future and which restore points created by future policy runs will graduate and be retained by which retention tiers.
Restore points graduate to higher retention tiers according to the retention schedule in effect when the restore point is created. This protects previous restore points when the retention schedule changes.
For example, consider a policy that runs hourly at 20 minutes after the hour and retains 1 hourly and 7 daily snapshots with the daily coming at 22:20. At steady state that policy will have 7 or 8 restore points. If that policy is edited to run at 30 minutes after the hour and retain the 23:30 snapshot as a daily, when the policy next runs at 23:30 it will retain the newly created snapshot as both an hourly and a daily. The 6 most recent snapshots created at 22:20 will be retained, and the oldest snapshot from 22:20 will be retired.
When editing the export location profile on a policy, the updated location profile should only be changed to a profile that references the same file or object store as the previous location profile. Failing to do so will result in the previously exported backups being inaccessible by Veeam Kasten.
Disabling Backup Exports In A Policy
Care should be taken when disabling backup/exports from a policy. If no independent export retention schedule existed, no new exports will be created and the prior exports will be retired as before. The exported artifacts will be retired in the future at the same time as the snapshot artifacts from each policy run.
If an independent retention schedule existed for export, editing the policy to remove exports will remove the independent export retention counts from the policy. Upon the next successful policy run, the snapshot retirement schedule will determine which previous artifacts to retain and which to retire based upon the policy's retention table. Retiring a policy run will retire both snapshot and export artifacts. Either snapshot or export artifacts for a retiring policy run may already have been retired if the prior export retention values were higher or lower than the policy retention values.
Deleting A Policy
A policy may be deleted from the Policies page, Policy View page, or through the API. However, for safety, deleting a policy does not remove the restore points it generated. Restore points from deleted policies must be manually deleted from the Application restore point view or via the API.
Upgrading a Policy
Periodic releases of Veeam Kasten include enhancements to improve backup data robustness and performance. In order to prepare the repository to take advantage of these enhancements, an upgrade may be required via each policy.
An eligible policy may be upgraded through the Upgrade menu option on the Policies page or by using the UpgradeAction API. Upgrading a Policy automatically upgrades all associated StorageRepositories.
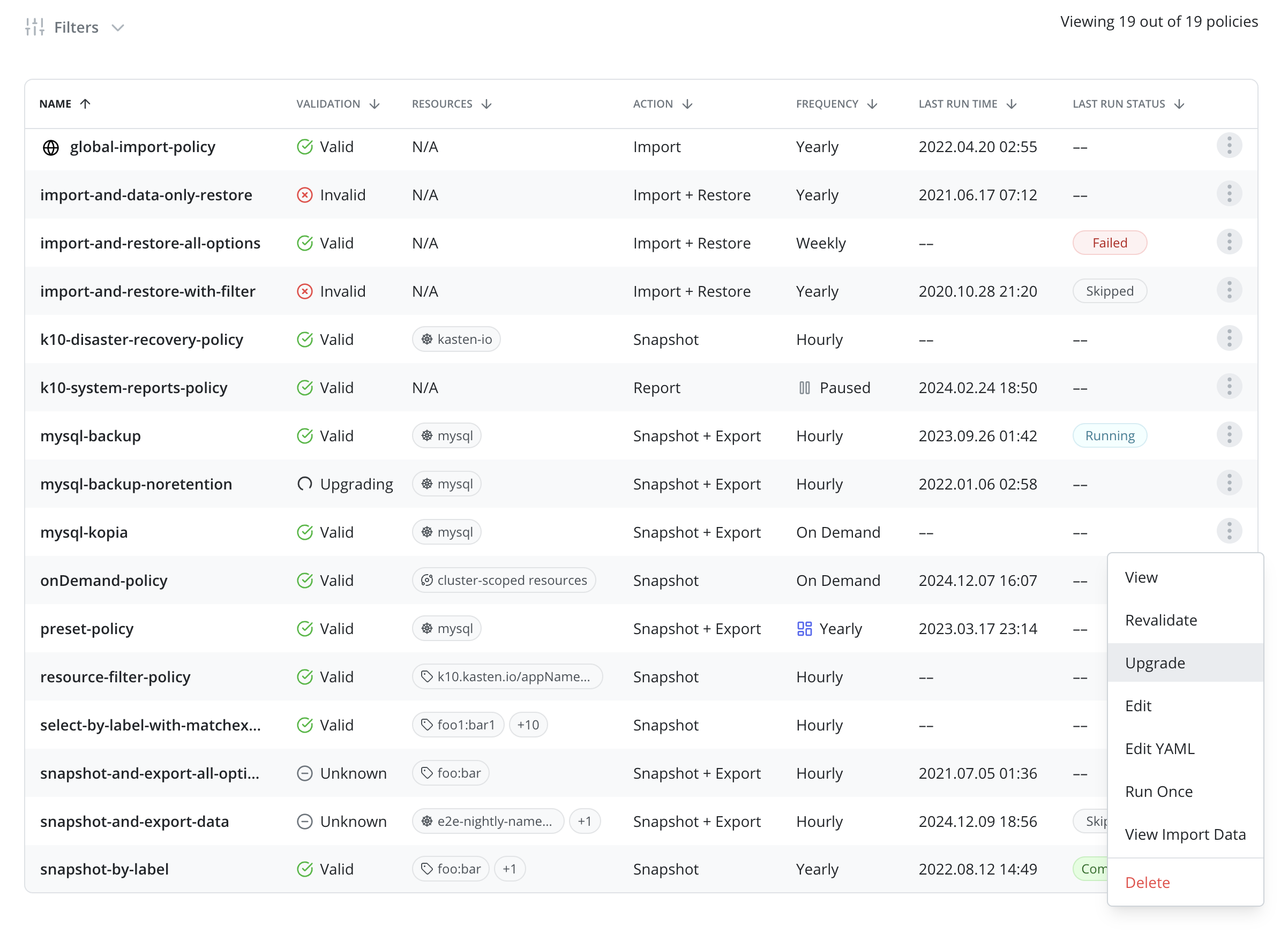
Depending on the specific Veeam Kasten release and the amount of data protected through a policy, an upgrade workflow may take anywhere from a few minutes to several hours to complete. Users are advised to plan downtime when scheduling upgrades. Upgrading a policy requires exclusive access to the underlying backup data and metadata. Currently, Veeam Kasten requires that no import or export actions be performed on a given policy while an upgrade is in progress. If a user attempts to upgrade an export policy while the policy is running or its restore points are being imported elsewhere, that operation will be interrupted. During a policy upgrade, imports and exports of restore points created by the same policy will be put on hold until the upgrade is complete.
In the event that a policy or repository upgrade is interrupted or fails unpredictably (for example, due to a network failure), the user should wait until all pending actions against the policy have completed. Afterward, the user may retry the upgrade. If the upgrade continues to fail unpredictably, please contact Kasten support.