Veeam Kasten Best Practices
Introduction
This guide describes the best practices for deploying Veeam Kasten on single or multiple Kubernetes environments. Veeam Kasten offers a powerful, flexible, enterprise-ready backup, recovery, and workload mobility solution for cloud-native applications.
Audience
This best practice guide, which is independent of any specific Kubernetes distribution, is aimed at users responsible for planning, designing, building, managing, and supporting applications deployed on Kubernetes. Users should be familiar with Kubernetes and its core concepts (e.g., deployments, pods, services, ingress, etc.), basic backup and recovery principles, and supporting infrastructure (such as storage, network, and compute).
Overview
This document includes information on the following topics:
- An overview of Veeam Kasten
- Best practices for deploying and using Veeam Kasten
Document Version History
| Version Number | Publish Dates | Notes |
|---|---|---|
| 1.0 | October 2023 | Original Publication |
Pre-Installation Planning
Business Continuity and Disaster Recovery Planning
Prior to deploying Veeam Kasten to backup Kubernetes workloads, we need to understand our overall approach for Business Continuity Planning (BCP) and Disaster Recovery (DR) planning. While having a robust backup tools for systems, infrastructure, and data is important, organizations also need to assess their operational readiness, approaches, responses, and logistics in the event of disasters, ransomware attacks, or other significant incidents.
Business Continuity Planning (BCP) and Disaster Recovery (DR) are closely related and often considered as complementary processes within an organization's overall resilience strategy. Although they have distinct areas of focus, they work together to ensure the organization's ability to withstand and recover from disruptive events.
While this guide is not comprehensive, it outlines various essential categories for consideration:
Business Continuity Planning
-
Operational Readiness: If a data center, remote office, or call center is rendered incapacitated, organizations need an operational plan to compensate for the loss of the site and minimize the impact on the business. Some examples may include:
- Designated individuals from different departments report to a different physical site.
- Office workers have secure remote access to business systems, data, and communication infrastructure, and this access is regularly tested and verified.
-
System Fallbacks and Workarounds: If a key business system (e.g., ERP, ordering and fulfillment system, Customer Relationship Management) goes offline, are secondary or fall-back processes available to compensate or "keep the lights on" for the business while systems and data are restored? For some organizations, this may be as simple as paper-based or manual systems.
-
Categorization and Prioritization of Business Systems and Data: Recognizing that all data and systems are equivalent within organizations, Cross-functional teams should collaborate to rank and prioritize systems, data, and infrastructure. This ensures that in the event of a disaster or outage, a documented order and/or prioritization of actions are defined.
-
Paper-based and Real-world Exercises: While having lists, plans, and workarounds defined is important, if they are not regularly tested, or are subject to failure when actually implemented, the impacts on the business are effectively the same as a complete outage. Organizations should plan to regularly audit, test, and update their Business Continuity and Disaster Recovery Plans to ensure they remain effective and relevant to the enterprise. This can be paper-based reviews or ideally, a simulated disaster event conducted semi-annually or annually.
Disaster Recovery
-
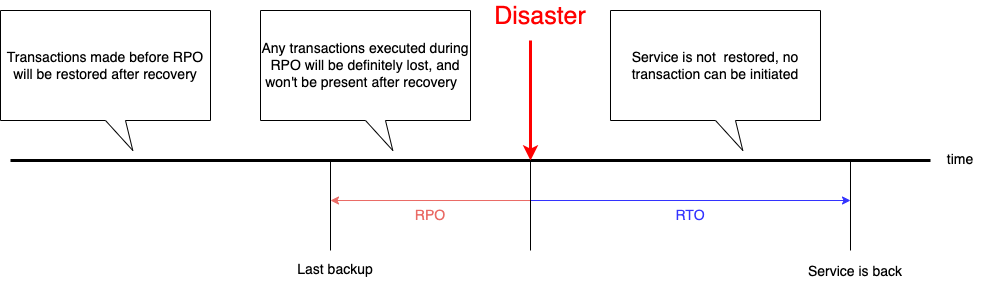
Definition of Recovery Time Objective (RTO) and Recovery Point Objective (RPO) for each system, application, and/or their relevant subcomponents: In conjunction with categorization and prioritization mentioned above, RTO and RPO definitions help organizations plan their infrastructure, backup policies, and overall approach to ensure the most critical systems and/or data have the lowest RTO and RPO (lower values are better, but typically more costly). While both are time measures, they address two different aspects:
- RPO is measured before a disaster. It represents the amount of time during which you may lose unrecoverable transactions prior to the disaster.
- RTO is measured after the disaster. It represents the time it will take to make your service available for new transactions.
-
3-2-1
Once we have defined all the numbers required for the sizing calculations, we need to have a look at the infrastructure estate. It is a best practice to follow the 3-2-1 rule:
-
Have at least three copies of your data.
-
Store the copies on two different media.
-
Keep one backup copy off-site.
Veeam Kasten can help you fulfill all 3-2-1 backup rule requirements:
-
Have at least three copies of data:
It is recommended to always have three copies of data. The three copies can be original data on the Persistent Volume Claim, the snapshot data and the snapshot exported to an external location.
-
Store the copies on two different media:
Veeam Kasten is storage and cloud-agnostic, meaning it supports multiple storage infrastructure, including block, file, and object storage. For example, storing your data on PVC and external S3 counts as two different media. Having two copies of data, one on PVC and the other as a local snapshot on the K8s cluster, does not count as two different media. In the event of a disaster and the cluster is beyond recoverable, both copies of data are lost.
-
Keep one backup copy off-site:
Set up backup copy jobs to transfer your backups off-site to another location (i.e. a Public Cloud Provider or secondary storage in a separate site). Exporting the backup to a location profile using NFS File Storage is not considered off-site.
-
-
Backup and Recovery Testing
Backups are only useful if they are recoverable. Simply targeting workloads and data for backup is not enough to ensure that organizations can withstand a disaster event, ransomware attack, or accidental deletion. Similar to the Business Continuity Testing described above, organizations should do a recovery test on their backups on a regular basis to make sure they are correct and can be restored. Such tests help organizations ensure that they meet their RTO and RPO targets.
-
Disaster Recovery Testing
In line with testing backup and recovery, organizations should aim to conduct a full Disaster Recovery test. Ideally, organizations should have an end-to-end documented DR plan in place, which includes people, processes, and systems documented ahead of time. This plan can serve as the "single source of truth" during both test exercises and real-world events. Organizations that have the most robust and/or mature Disaster Recovery plans and infrastructure will regularly run through partial or full DR tests in production environments (e.g., fail over from Data Center A to Data Center B, operate out of Data Center B for a set time, before failing back to Data Center A).
-
Object storage immutability
Veeam Kasten allows you to prohibit the deletion of data in object storage repositories by making the data temporarily immutable. This is done to enhance security and protect your data from loss due to attacks, malware activity (e.g., ransomware), or other actions.
Target Workloads
Veeam Kasten provides complete backup and recovery capabilities for applications and persistent data deployed within a Kubernetes cluster. This allows users the ability to restore namespaces on the same or different K8s cluster(s).
Veeam Kasten can protect both applications and data in single or multiple Kubernetes namespaces, as well as cluster-scoped resources that are not associated with namespaces. When Veeam Kasten protects cluster-scoped resources, by default, all instances of StorageClasses, CustomResourceDefinitions, ClusterRoles, and ClusterRoleBindings are captured in a cluster restore point. Resource filtering can be used to restrict which cluster-scoped resource instances are captured or restored.
Example Use Cases
The table below summarizes the different combinations for backing up, restoring, and/or migrating workloads:
| Source | Destination | Notes |
|---|---|---|
| Public Cloud “A” | Public Cloud “A” | Restore an application and its data to the same cluster on which it was originally deployed (e.g., validation of a backup, restoration following an accidental deletion, or a failed roll-out of an application) |
| Public Cloud “A” | Public Cloud “B” | Restore an application and its data from one Kubernetes cluster on a public cloud to another Kubernetes cluster on the same or a different public cloud provider (e.g., Disaster Recovery, or Application Mobility) |
| Public Cloud “*” | Private Cloud “*” | Restore an application and its data from a Kubernetes cluster on a public cloud to another Kubernetes cluster on a private cloud (e.g., Disaster Recovery, or Application Mobility) |
| Private Cloud “A” | Private Cloud “A” | Restore an application and its data to the same cluster on which it was originally deployed (e.g., validation of backup, restoration following an accidental deletion, or a failed roll-out of an application) |
| Private Cloud “A” | Private Cloud “B” | Restore an application and its data from one Kubernetes cluster on a private cloud to another Kubernetes cluster on the same or a different private cloud (e.g., K8s upgrade, Disaster Recovery, or Application Mobility) |
| Private Cloud “*” | Public Cloud “*” | Restore an application and its data from a Kubernetes cluster on a private cloud to another Kubernetes cluster on a public cloud (Disaster Recovery, or Application Mobility) |
| Edge Device | Public or Private Cloud “*” | Backup an application from an edge device to a private or public cloud |
| Public or Private Cloud “*” | Edge Device | Move or restore workloads from a centralized cluster to an edge device |
Supported Storage
Veeam Kasten highly recommends using a storage system with a CSI supported driver that includes VolumeSnapshot Support. Using a CSI driver with VolumeSnapshot support is a requirement to build a good Data Protection solution using Veeam Kasten. Though Veeam Kasten supports Generic Storage Backups (GSB) for storage systems with no CSI drivers, this approach is NOT recommended. For more information on CSI integration requirements and supported storage, refer to the Storage section of the Veeam Kasten Documentation .
Advanced Application Workloads
In addition to its storage-based Volume Snapshot capabilities, Veeam Kasten supports advanced application workloads that may require application-specific data management tasks such as pausing a database prior to backup or migration. Veeam Kasten can leverage Kanister Blueprints for pre and post-backup hooks to accommodate these advanced workloads. For more information about application-level data management within Kubernetes, refer to the Extending Veeam Kasten with Kanister Documentation.
Generic Storage Backups
- Remember that most of the NFS storage services available on the market today do not provide a CSI driver with snapshot and clone capabilities. It is highly recommended to migrate persistent data from NFS to a storage system that provides a CSI driver with these capabilities. To find out if a CSI driver is compatible with your matrix, visit this page: Drivers - Kubernetes CSI Developer Documentation.
- If you are in this situation, Veeam Kasten can help with a migration project by leveraging a feature called Generic Storage Backups (GSB). Effectively, Generic Storage Backups use a simple file-copy-based operation to back up persistent data to an external location and then leverage the backup to restore it to a storage that provides the CSI driver with snapshot and clone capabilities.
- If you require further guidance or support for such a migration project, please feel free to reach out to your local Veeam contact, who can connect you with the Kasten Specialist team.
Installing and Configuring
Installation Approach
- Include Veeam Kasten deployment and configuration as part of a GitOps solution. Veeam Kasten is designed to protect Kubernetes applications and cannot be used to deploy or restore cluster's overall state. To ensure automated and consistent deployment of Kubernetes clusters, including configurable infrastructure components such as service mesh and other operator deployments, consider using tools such as scripts, Terraform, Ansible, CloudFormation, etc. By automating the deployment of Veeam Kasten, whether through Helm or Operator, as part of the same solution, you can rapidly recover both applications and data using Kasten Veeam Kasten in the event of an entire cluster loss.
- Validate that all prerequisites for installing Veeam Kasten are met by running the Pre-Flight checks. Refer to the Veeam Kasten documentation for additional information on the Pre-Flight Checks.
- Do not leave the dashboard behind port-forward; use an ingress with HTTPS.
Primary Storage
- For Kubernetes platforms that offer both CSI and in-tree storage provisioner options, always choose the CSI provisioner. CSI drivers represent the future of storage operations in K8s as the legacy in-tree plugin-based provisioners have already been deprecated and will be removed in subsequent versions of K8s. The PVCs provisioned by these legacy in-tree provisioners are being migrated to CSI drivers.
- Verify that any CSI storage provisioners support VolumeSnapshots. This may be indicated in the documentation from the storage provider, but it can also be validated using Veeam Kasten Tools. Veeam Kasten strongly recommends using a CSI storage provisioner as a prerequisite.
- Verify, using storage provisioner documentation, any limitations on the total number of snapshots per persistent volume claim, as this may impact policy retention settings.
- Ensure the VolumeSnapshotClass has the required Veeam Kasten annotation to leverage CSI Volume Snapshots. Check Veeam Kasten documentation for additional information on Storage Integration and the required configuration.
Export Storage
- When choosing a target for backup exports (aka Location Profiles), it is advisable to prioritize object storage over NFS/SMB. Object storage solutions (S3, S3-Compatible, Azure Blob, and Google Cloud Storage) provide multiple benefits over NFS/SMB. These solutions are designed to work across multiple data centers under a single namespace, and can be made more durable than NFS/SMB by distributing copies to multiple locations. It is more scalable and easier to manage when compared to NFS/SMB. Additionally, Azure, S3 and S3-compatible solutions can be configured to mitigate ransomware attacks by enabling object locking and versioning to store immutable copies of your backup data.
- Specific to VMware Tanzu clusters, Veeam Kasten supports Changed Block Tracking (CBT) to efficiently backup Persistent Volumes. This feature is extremely useful and improves performance when backing up large PVCs on VMware. For additional details, refer to the Block Mode Export section. Note that enabling CBT in the Veeam Kasten policy requires Tanzu Advanced licenses. Refer to the URL for additional details.
Authorization and Authentication
- Choose an authentication provider. Authentication is required to configure permanent external access to the Veeam Kasten Dashboard. A multi-user authentication solution such as OpenID Connect, Active Directory/LDAPS, OpenShift OAuth, or Kubernetes bearer tokens is recommended in order to leverage RBAC capabilities. It is recommended to integrate Veeam Kasten with existing identity and access management (IAM) systems.
-
Exercise caution in granting the built-in
k10-adminClusterRole to groups and users, as this allows for all actions, including the removal or modification of data protection policies and the removal of backup data (RestorePoints). - Define custom K8s ClusterRoles and RoleBindings/ClusterRoleBindings to limit user or group access to the required actions and namespaces.
- Ensure that RBAC bindings are properly applied when using an alternate authentication solution for Kubernetes API access.
Multi-Cluster
- When managing more than a single Kubernetes cluster, configure the Veeam Kasten Multi-Cluster Dashboard to provide centralized visibility and management of profiles, policies, and licensing.
- Multi-cluster RBAC is independent of ClusterRoles or Bindings applied to individual clusters. Review the capabilities of the built-in multi-cluster RBAC profiles and create bindings.
Multi-cluster K10ClusterRoles are applied at a per-cluster level and cannot be used to limit access at a per-namespace level. Access to the multi-cluster dashboard should be reserved for administrators.
- The GitOps process to rebuild the Kubernetes cluster and Kasten after a disaster should also include joining secondary clusters to the primary Veeam Kasten cluster.
- Licenses can be installed on individual clusters or on the primary cluster in a multi-cluster configuration.
- When managing more than one Kubernetes cluster, enabling multi-cluster management is recommended as it allows a shared licensing model rather than licensing each Kubernetes cluster separately. Licenses will be pooled in a multi-cluster configuration.
Security and Secret Management
- Kasten's encryption is always enabled and generates a random passphrase during installation when a secret is not provided. It is recommended to create your custom keys and provide them during installation.
- Use AWS Customer Managed Keys (follow the instructions at this location) or HashiCorp Vault (see instructions here) to protect the primary key used by Veeam Kasten to encrypt application data.
- Use a secret from AWS Secrets Manager or HashiCorp Vault to provide a passphrase that encrypts Veeam Kasten disaster recovery backups is recommended.
- Ensure the cluster ID generated when enabling Veeam Kasten DR is stored securely as it is needed during the restore process.
- Using the self-signed certificates created during Veeam Kasten install can lead to a security risk. It is highly recommended to create a configmap with custom certificates from a trusted root certificate authority and specify the configmap during Veeam Kasten installation.
Special Considerations for Air-Gapped Environments
- Use the
k10tools imagecommand to automate the process of obtaining the images required for Veeam Kasten to your private registry. - During the installation of Veeam Kasten, make sure to configure the metering mode to "airgap" for optimal performance and security.
Managing and Operating
Data Management
-
Retention: To optimize storage costs, it's recommended to reduce local retention, which can be more expensive, and increase remote retention, which is typically more cost-effective. When configuring retention policies, it's essential to strike a balance to prevent storage from being filled up.
You have the flexibility to define multiple retention policies with different time periods for your workloads. For instance, Policy 1 could schedule two daily snapshots of an application without exporting it. On the other hand, Policy 2 could capture two additional snapshots per day and then export the application. This approach would help to effectively manage the storage space locally and remotely.
To further optimize storage usage, Veeam Kasten automatically employs deduplication and compression techniques on exports, helping to conserve space while retaining data integrity. This ensures efficient utilization of your storage resources and cost-effective data protection.
-
Multi-tenancy and RBAC: To enhance the efficiency and flexibility of Veeam Kasten, consider implementing multi-tenancy and transforming it into a backup-as-a-service model, rather than restricting its usage to a select group of trusted users. This approach enables effective user management based on the principle of least privileges while also facilitating self-service capabilities.
By adopting multi-tenancy, you can assign appropriate privileges to different users or teams, ensuring that they have access only to the resources necessary for their specific tasks. This not only enhances security but also streamlines the backup management process.
Furthermore, transitioning to a backup-as-a-service model empowers developers and application teams to take more ownership of their data protection. They can create and manage their own backup policies, set backup schedules, and determine data retention settings, providing them with the autonomy and flexibility to tailor the backup process to their specific needs.
-
System Namespaces and ETCD: Kasten does not recommend backing up control-plane components like etcd and system namespaces. Its primary focus is on ensuring data protection and mobility for applications within Kubernetes. For the control-plane components, it is generally advised to follow Kubernetes best practices and use specific tools or procedures designed for their backup and restoration. In the case of cluster failures, it is often more efficient to restore your applications to a new cluster using Kasten backups rather than investing time and effort in repairing the failed cluster and restoring it from etcd backups. This approach streamlines the recovery process and helps ensure the continuity of critical applications without the need to deal with the complexities of cluster-level restoration.
-
Operator based Apps: When safeguarding Kubernetes operators, it is essential to gain a comprehensive understanding of their functionalities. Devise a well-defined strategy for backing up and restoring each operator, conduct thorough restoration tests, and meticulously document the process. When the operator provides an API for backup and restore actions, the objective is to leverage Veeam Kasten Blueprint through Kanister. Kanister will request the operator to backup or restore the resources it controls. Rather than Veeam Kasten working with the resource directly, it is much more efficient to leverage Kanister to work in collaboration with the operators.
-
Database backups with Kanister: Check if your database supports storage snapshot backups and try to leverage the Kanister framework to create a blueprint for database backups whenever possible. Native database backups offer efficiency and reliability, while Kanister provides a flexible solution for orchestrating backups across diverse environments, ensuring data protection and simplified management. It is recommended to prioritize application-consistent backups over logical backups. Application-consistent backups ensure that the data and application state are consistent, reducing the risk of data corruption and ensuring a more reliable and seamless recovery process while harnessing the power of the local storage snapshot process. Logical backups, which involve creating a database dump, do maintain consistency and are often used for data migrations, transfers, or portability purposes. While logical backups ensure consistency, they are usually full backups where the database is dumped every time during the backup and lack the swiftness of storage-level snapshots. You can access a comprehensive guide to Kanister, including instructions for creating downloadable Blueprints, at the following location.
Disaster Recovery
Veeam Kasten supports Disaster Recovery capabilities directly within the product, provided there is a location profile configured to send backup data (e.g., S3 or S3-compatible object storage, NFS/SMB, Veeam VBR Repository). Ideally, the storage used supports immutability to ensure protection against ransomware or malicious or accidental deletion.
It is mandatory to always enable Disaster Recovery within Veeam Kasten to recover the applications in the event of a disaster. In situations similar to cluster upgrades or major cluster modifications, this proactive approach ensures data protection and facilitates seamless recovery if needed.
In addition to recovering Veeam Kasten itself, application workloads can be recovered via backups, which can be restored at a secondary site.
Veeam Kasten supports two primary methods for ensuring resiliency in the event of a disaster scenario:
| Strategy | Recovery Time | Cost (Infrastructure) | Use Case |
|---|---|---|---|
| Rebuild | High | Low | Pre-production / small organizations with constrained budgets |
| Replicate | Medium | High | Production and/or Enterprise Workloads |
The Rebuild approach requires the most effort (and therefore, the most time) to restore in the event of a disaster, but has minimal costs and standby infrastructure is required.
The Replicate approach reduces effort as it supports a Hot/Standby or Hot/Warm approach where recovery point data and/or persistent storage is "pre-seeded" in the secondary site.
- Rebuild
a. Configure policies to export backups to an off-site location.
b. Enable Disaster Recovery for Veeam Kasten to export the Veeam Kasten catalog to external storage using a user-provided passphrase key or via third-party management for the secret to encrypt the catalog data.
c. In the event of a complete cluster or site loss, a new cluster can be deployed in a secondary site or the public cloud.
d. Veeam Kasten can be redeployed via Helm, and a Location Profile can be created to point to the off-site data repository.
e. The Veeam Kasten catalog can be imported (via the previously set passphrase) to the new instance of Veeam Kasten.
- Replicate
a. Configure policies to export backups to an off-site location (e.g., S3 or S3-compatible object storage, NFS/SMB, Veeam VBR Repository, etc.).
b. Configure import policies from secondary storage to import restore point data from a source Veeam Kasten catalog (this can be scheduled to occur at a set frequency).
c. (Optional) Leverage Transforms to modify spec data to scale down workloads during import/restore (for example, if the primary site has three replicas, set replicas to zero). In the event of a failure on the primary site, worker nodes can be spun up and replicas adjusted to spin up applications on the secondary site.
For more details on how to implement Veeam Kasten Disaster Recovery, refer to the Veeam Kasten Documentation on Disaster Recovery.
Monitoring and Alerting
- Use Prometheus: Veeam Kasten has a feature that provides metrics about its activities. Set up Prometheus to gather these metrics and keep track of backups, restores, and overall system health.
- Integrate with Grafana: Grafana is a tool that helps visualize the metrics from Prometheus. Create a dashboard in Grafana that displays important metrics for easy tracking.
- Set Up Alerting: Configure Veeam Kasten to send alerts when certain metrics exceed critical levels. In this way, you can quickly identify and fix issues.
See the Veeam Kasten documentation for more details on creating Grafana alerts based on Veeam
Kasten metrics. It is recommended to create alerts for any actions
where state=failed and Catalog Volume Used Space > 50%, as this
condition could impact Veeam Kasten upgrades.
- Monitor Regularly: Regularly check the metrics and logs of your Veeam Kasten system. This practice helps you discover and fix problems before they lead to downtime or data loss.
- Update Monitoring Configuration: As your Veeam Kasten setup evolves, keep your monitoring configuration up-to-date. This ensures you monitor the right metrics and receive alerts for new issues.
Creating and Managing Policies
- Use PolicyPreset to standardize backup and export retention across policies.
- Avoid creating a policy with a wildcard namespace selector. Instead, create policies per application or per application group and make use of the backup window and staggering to utilize the intelligent policy scheduling capabilities of Veeam Kasten. This approach will reduce the load on both Veeam Kasten and the cluster API.
- Configure a dedicated policy for protecting Cluster-scoped resources.
- Use labels to target specific resources with your policies. This can be helpful if you want to apply the same policy to a group of resources.
- Consider shorter duration on Snapshots and extended periods for Exports.
- Define a backup window that does not conflict with multiple policies to prevent system overload.
- Make sure to regularly verify the readiness of your applications. If your applications are scaled down, experiencing issues, or not functioning correctly, you should enable the "Ignore Exceptions and Continue if Possible" option in the policy actions to ensure they are carried out to the best of their ability.
Testing Backup and Restore
- Test restores regularly; do not wait for a disaster to happen. Test application restores within the same namespace, in a different namespace on the same Kubernetes cluster, and on different clusters.
- Test granular application restores and full application restores. Use Veeam Kasten Transforms to make changes to application manifests during the restoration process.
- Restore applications based on priority to meet RTO requirements.
- Veeam Kasten catalog backup and restore are handled through a dedicated disaster recovery process, which is documented at Veeam Kasten Disaster Recovery. It is recommended to enable Veeam Kasten DR and regularly test the Veeam Kasten DR process.
Veeam Kasten Tools
- Explore additional tools and utilities provided by Kasten that can enhance your experience with Veeam Kasten. For more information on Veeam Kasten Tools, see this page .
- Stay updated on new tools and features released by Kasten to leverage their benefits. Access Kasten's release notes by clicking this link.
Maintenance and Upgrades
- Always upgrade; we are constantly fixing bugs and adding important features (Kasten releases every 2 weeks), so do not stay on an outdated version for comfort.
- Veeam Kasten needs at least 50% free space in Catalog Storage for upgrades. Check the Veeam Kasten dashboard under Settings → Support → Upgrade status for details on the current version, latest version, and catalog storage space. For additional details on the Veeam Kasten upgrade, refer to the Veeam Kasten user guide.
Additional Resources
- Veeam Kasten User Guide: Veeam Kasten
Docs.
- Provides core product deployment, configuration, and operation details and instructions.
- Veeam Kasten Helm Chart Wizard: Helm Command
Generator.
- Form builder to key in the values and generate the helm command for Veeam Kasten install.
- Veeam Kasten Resources: Kubernetes
Resources.
- Provides blogs, how-to guides, product videos, case studies and more.
- Veeam Kasten Knowledge base: Help
Center.
- Provides articles on advanced configuration and troubleshooting.
- Kasten by Veeam YouTube Channel: YouTube
Channel.
- Provides webinar recordings, product demos, and how-to videos.
- KubeCampus: Courses.
- Provides hands-on learning experiences covering Kubernetes and Kasten fundamentals.