etcd Backup (OpenShift Container Platform)
Assuming the Kubernetes cluster is set up through OpenShift Container Platform,
the etcd pods will be running in the openshift-etcd namespace.
Before taking a backup of the etcd cluster, a Secret needs to be created
in a temporary new or an existing namespace, containing details about
the etcd cluster endpoint, etcd pod labels and namespace in which the etcd pods
are running. In the case of OCP, it is likely that etcd pods have
labels app=etcd,etcd=true and are running in the namespace
openshift-etcd.
A temporary namespace, and a Secret to access the etcd member can be created by
running the following commands:
$ oc create ns etcd-backup
$ oc create secret generic etcd-details \
--from-literal=endpoints=https://10.0.133.5:2379 \
--from-literal=labels=app=etcd,etcd=true \
--from-literal=etcdns=openshift-etcd \
--namespace etcd-backup
Note
Make sure that the provided endpoints, labels and etcdns values
are correct. K10 uses the labels provided above to identify a member of the
etcd cluster and then takes backup of the running etcd cluster.
To figure out the value for endpoints flag, the below command can be used:
$ oc get node -l node-role.kubernetes.io/master="" -ojsonpath='{.items[0].status.addresses[?(@.type=="InternalIP")].address}'
To avoid any other workloads from etcd-backup namespace being backed
up, Secret etcd-details can be labeled to make sure only this Secret
is included in the backup. The below command can be executed to label the
Secret:
$ oc label secret -n etcd-backup etcd-details include=true
Backup
To create the Blueprint resource that will be used by K10 to backup etcd, run the below command:
$ oc --namespace kasten-io apply -f \
https://raw.githubusercontent.com/kanisterio/kanister/0.69.0/examples/etcd/etcd-in-cluster/ocp/etcd-incluster-ocp-blueprint.yaml
Once the Blueprint is created, the Secret that was created above needs to be annotated to instruct K10 to use this Secret with the provided Blueprint to perform backups on the etcd pod. The following command demonstrates how to annotate the Secret with the name of the Blueprint that was created earlier.
$ oc annotate secret -n etcd-backup etcd-details kanister.kasten.io/blueprint='etcd-blueprint'
secret/etcd-details annotated
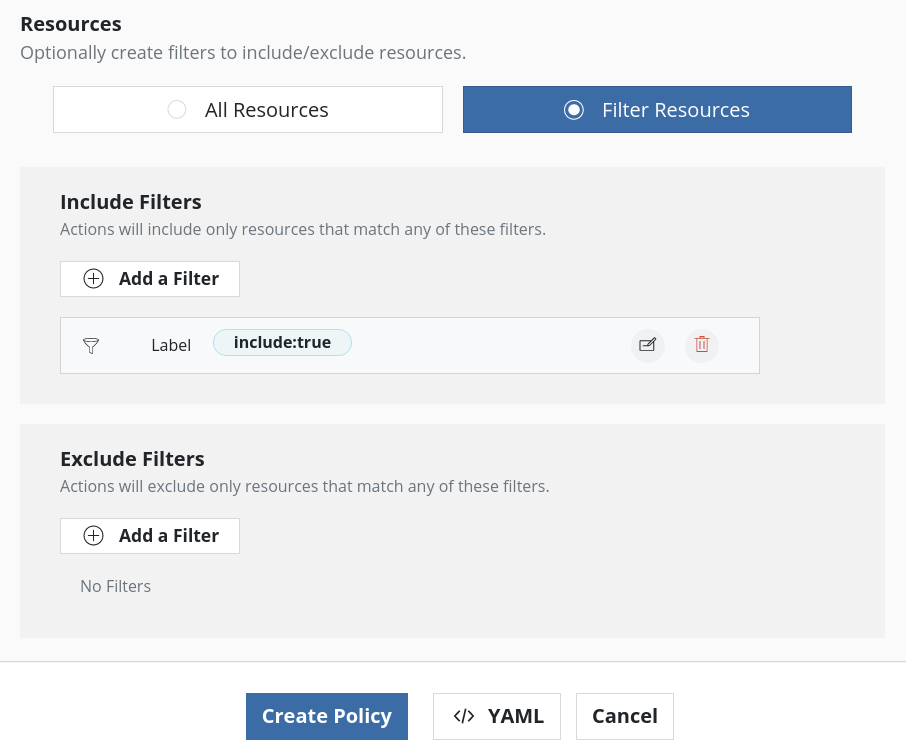
Once the Secret is annotated, use K10 to backup etcd using the new namespace. If the Secret is labeled, as mentioned in one of the previous steps, while creating the policy, just that Secret can be included in the backup by adding resource filters like below:
Note
The backup location of etcd can be found by looking at the Kanister artifact of the created restore point.
Restore
To restore the etcd cluster, the same mechanism that is documented by
OpenShift
can be followed with minor modifications. The OpenShift documentation provides
a cluster restore script (cluster-restore.sh), and that restore script
requires minor modifications because is expects the backup of static pod
manifests as well which is not taken in this case. The modified version of
the restore script can be found on here.
Before starting the restore process, make sure these prerequisites are met:
SSH connectivity to all the leader nodes
Among all the leader nodes, choose one node to be the restore node
A command-line utility to download etcd backup from object store (e.g., the
awsCLI)
The below steps should be followed to restore the etcd cluster:
Download the etcd backup on the restore node using the
awsCLI to a specific location (e.g.,/var/home/core/etcd-backup):Stop static pods from all other leader nodes by moving them outside of
staticPodPathdirectory (i.e.,/etc/kubernetes/manifests):# Move etcd pod manifest $ sudo mv /etc/kubernetes/manifests/etcd-pod.yaml /tmp # Make sure etcd pod has been stopped $ sudo crictl ps | grep etcd # Move api server pod manifest $ sudo mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmp
Move the etcd data directory to a different location, on all leader nodes that are not the restore nodes:
$ sudo mv /var/lib/etcd/ /tmpRun the modified
cluster-ocp-restore.shscript with the location of etcd backup:$ sudo ./cluster-ocp-restore.sh /var/home/core/etcd-backupRestart the
Kubeletservice on all of the leader nodes:$ sudo systemctl restart kubelet.serviceVerify that the single etcd node has been started:
$ oc get pods -n openshift-etcd NAME READY STATUS RESTARTS AGE etcd-ip-10-0-149-197.us-west-1.compute.internal 1/1 Running 0 3m57s installer-2-ip-10-0-149-197.us-west-1.compute.internal 0/1 Completed 0 7h54m installer-2-ip-10-0-166-99.us-west-1.compute.internal 0/1 Completed 0 7h53m installer-2-ip-10-0-212-253.us-west-1.compute.internal 0/1 Completed 0 7h52m revision-pruner-2-ip-10-0-149-197.us-west-1.compute.internal 0/1 Completed 0 7h51m revision-pruner-2-ip-10-0-166-99.us-west-1.compute.internal 0/1 Completed 0 7h51m revision-pruner-2-ip-10-0-212-253.us-west-1.compute.internal 0/1 Completed 0 7h51m
Force etcd deployment, by running the below command:
$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge # Verify all nodes are updated to latest version $ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}' # To make sure all etcd nodes are on the latest version wait for a message like below AllNodesAtLatestRevision 3 nodes are at revision 3
Force rollout for the API Server control plane component:
# API Server $ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge
Wait for all API server pods to get to the latest revision:
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'
Force rollout for the Controller Manager control plane component:
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge
Wait for all Controller manager pods to get to the latest revision:
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'
Force rollout for the Scheduler control plane component:
$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge
Wait for all Scheduler pods to get to the latest revision:
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'
Verify that all the etcd pods are in the running state. If successful, the etcd cluster has been restored successfully
$ oc get pods -n openshift-etcd | grep etcd
etcd-ip-10-0-149-197.us-west-1.compute.internal 4/4 Running 0 19m
etcd-ip-10-0-166-99.us-west-1.compute.internal 4/4 Running 0 20m
etcd-ip-10-0-212-253.us-west-1.compute.internal 4/4 Running 0 20m